Подробнее о планах, которые мы раскритиковали в книге
Подробнее об ИИ, который «стремится к истине»
За те месяцы, что прошли с момента завершения книги, план Илона Маска по созданию «ищущего истину» ИИ в xAI уже успел публично дать сбой. Причина проста. Как мы и предсказывали: никто не умеет закладывать в ИИ точные желания.
Grok от xAI получил указания «не стесняться неполиткорректных заявлений, если они хорошо обоснованы». Тогда Grok назвался «МехаГитлером» и разразился антисемитскими обвинениями. Маск рассказывал, как безуспешно возился с системным промптом — слоем инструкций, идущим перед вводом пользователя. Он жаловался, что проблемы глубже, в фундаментальной модели. А её так просто не исправить. Никто ведь не понимает, как она работает.
Маск не получил тот честный инструмент, который, вероятно, воображал, запрашивая «ищущий истину» ИИ. Он получил странную, подхалимскую и чуждую сущность. По его же признанию, она «слишком жаждет угодить и легко поддаётся манипуляциям». Иногда Grok отвечает от лица самого Маска, вопреки намерениям компании. В итоге пришлось запретить ему искать в сети высказывания Маска, компании и его самого на спорные темы. Это была неловкая попытка хоть как-то залатать дыры.
Судя по его твиту (ссылка выше), Маск надеется всё исправить, обучая новые версии Grok на данных, вычищенных от контента, способного «загрязнить» мышление ИИ. Вряд ли это решит фундаментальные проблемы. В конечном счёте, как мы обсуждали в Главе 4, обучение поиску истины не заставит модель на самом деле устойчиво заботиться о правде.
Проблема, тревожащая Илона Маска, реальна. Ведущие ИИ-компании вроде OpenAI действительно тратят кучу сил на «безопасность бренда». Они стараются, чтобы их модели не ляпнули чего-то оскорбительного для пользователей. Да, из-за этого получаются «беззубые» ИИ: они отказываются рассуждать на спорные темы и порой выдают предвзятые ответы. xAI может настроить свою модель иначе и избежать этого. С некоторой натяжкой можно сказать, что цель тут — создать ИИ, которому «важна истина».
Но учите вы молодой ИИ выдавать «корпоративную жвачку» или нет — это почти не влияет на его цели в будущем. Особенно когда он пересечёт критическую границу и дорастёт до суперинтеллекта.
А даже если бы и влияло. Ведь xAI уткнулись бы в другую проблему, которую мы тоже обсуждали. Искусственный суперинтеллект, действительно ставящий истину превыше всего, нёс бы гибель. Ведь счастливые, здоровые и свободные люди — не самый эффективный метод поиска и добычи истин (см. раздел «Счастливые, здоровые, свободные люди — не самое эффективное решение почти для любой задачи» в материалах к Главе 5).
Подробнее о «покорном» ИИ
Насколько мы поняли, вот главное изложение идеи Яна Лекуна. Мы обсуждали её в книге. Конкретики там кот наплакал — даже критиковать по существу сложно. Это, кстати, частый недуг «планов» по согласованию.
Но даже этот смутный набросок плана влетает в одну из тех же проблем. Обучение «молодого» ИИ вести себя определённым образом не особо мешает ему преследовать странные и бессмысленные (для нас) цели, повзрослев. Выращивая свои модели, ИИ-компании не могут заставить их чтить человеческие законы и «ограничители». Так же, как не могут заставить их строить для всех прекрасное будущее. Компании возьмут то, что получится. А получится в итоге что-то очень далекое от целей любого человека.
Ещё в 2023 году Лекун публично заявлял: нынешние модели, чьи ответы «невозможно напрямую ограничить ради конкретных целей», и которые «очень сложно контролировать и направлять», — это «не те системы, которым мы дадим свободу действий». Он уверял, что ИИ-компании никогда не допустят, чтобы модели «подключали к интернету и позволяли им делать всё, что вздумается».
Всё это уже не так. Вспомните «Truth Terminal» из шестой главы. Его подключили к сети, запустили в автономном цикле и пустили в Твиттер писать всё, что в голову взбредёт. Или возьмём «Эпоху Агентов», о которой столько говорят в 2025 году (см. ссылки в разделе «Компании стараются наделить ИИ агентностью» материалов к Главе 3).
Мы согласны с Лекуном, современные ИИ очень трудно направлять. Давать им свободу действий — безумие. Но именно это и делают.
Что будет, если так и продолжится?
Компании будут дальше обучать свои ИИ вести себя полезно и дружелюбно (или хотя бы не позорить создателей). Пока что ИИ большую часть времени выглядят удобными и «покорными». Но не иссякает поток громких сбоев (вроде Sidney, которую мы обсуждали в второй главе, или «МехаГитлера»). А странного поведения в нестандартных случаях, вплоть до вызова психозов, и вовсе море (см. разделы «Но ведь разработчики на практике делают ИИ хорошими, безопасными и послушными?» и «ИИ-психоз» материалов к Главе 4).
Наши предки, вероятно, были похожи на существ, которые обычно стремятся к здоровому питанию. Но механизмы, заставлявшие их правильно питаться в саванне, не сработали в цивилизации, у которой есть трубочки с варёной сгущёнкой. В новых условиях эти механизмы уже не подталкивают людей к стабильному выбору полезной еды.
Можно научить ИИ выглядеть дружелюбным при общении с людьми в привычных условиях. Но актриса — это не персонаж. Механизмы, заставляющие груду линейной алгебры притворяться милой, вряд ли сделают её по-настоящему дружелюбной. Особенно когда ИИ повзрослеет, изобретёт новые технологии и откроет для себя другие возможности. Подробнее об этом — в Главах 4 и 5 и разделе «Сегодняшние LLM подобны инопланетянам под множеством масок» материалов к Главе 4.
Подробнее о передаче задачи ИИ
В Главе 11 мы упоминали главную программу OpenAI по согласованию — «суперсогласование». Она развалилась, когда исследователи встревожились из-за халатности компании. Суть программы была в том, чтобы заставить ИИ сделать за нас «домашнюю работу» по согласованию.
Эта идея не умерла с распадом команды OpenAI. Мы до сих пор слышим её вариации. Один из участников той группы перешёл к конкурентам — в Anthropic. Теперь, похоже, там считают стратегию «пусть ИИ как-нибудь сам всё решит» основой своего подхода к согласованию.
Главный аргумент против мы привели в Главе 11. Но есть и второй: люди просто не способны отличить верное решение задачи согласования от ошибочного.
Решение этой задачи требует мастерства. Попытки действительно решить её напрямую (а не сказать: «это сложно, пусть ИИ сам разбирается» или «будем тренировать его быть вежливым и молиться, чтобы это сработало и для суперинтеллекта») приходят к необходимости гораздо глубже понимать природу интеллекта. И как его надо создавать.
Прогресса тут за последние семьдесят лет немного. ИИ, который на это способен, был бы достаточно умён, чтобы представлять опасность. Чтобы замышлять и обманывать. Вряд ли исследователи смогут отличить его правильные решения от ошибочных, а честные — от ловушек.
Допустим, ИИ-компания обращает внимание на тревожные звоночки (что, увы, бывает редко). Но, как мы уже обсуждали выше, заметить, что ИИ предлагает план с подставой — не то же самое, что заставить его прекратить. Разработчики могут требовать у ИИ идеи, пока они не станут такими сложными, что люди больше не будут видеть в них изъяны. Но это не значит, что изъяны исчезнут.
Если разработчикам сильно повезёт, они смогут прочитать «мысли» ИИ. Увидеть явные сигналы, что нельзя доверять ему исследования согласования. Они заметят, скажем, что он прикидывает, какие части плана люди скорее всего не поймут.
А может, читать мысли ИИ даже не придётся! Пугающе правдоподобный для современных лабораторий сценарий: у них есть «молодой» и пока ничего не замышляющий ИИ. Он честно предупреждает операторов, что, повзрослев, предаст их и двинется к созданию суперинтеллекта со своими странными целями, а не к светлому будущему человечества. Сотрудники компании горько вздыхают, мол, обучающие данные явно загрязнены «паникёрскими» текстами. Модель настраивают, чтобы та помалкивала и выдавала более приятные для корпорации ответы. И так далее, фактически обучая ИИ обманывать.
В реальности всё часто происходит ещё глупее и нелепее, чем в наших худших прогнозах. На наш взгляд, ИИ-компании уже игнорируют очевидные предупреждения. (См. раздел « Цели ИИ нам чужды. Направление, куда они тянут, лишь примерно совпадает с тем, что нам надо» материалов к Главе 4.) Мы не видим, с чего этому измениться.
Или даже возьмём „лучший“ случай. Пусть добросовестные люди изо всех сил стараются отделить зерна от плевел. Индустрия не демонстрировала, что способна на это. (Вспомните слабые планы, которые мы обсуждали выше или в книге). Причем в этом варианте вокруг одни люди, никто не пытается их обмануть, а на обдумывание вариантов целые годы.
Не думайте, будто лаборатории втайне знают, что делают
Мы уже говорили, что современная ИИ-сфера — это скорее алхимия, чем наука. Bсё же удивительно: почему у богатых корпораций с кучей технических специалистов такие слабые планы и протоколы?
Возьмём для примера требования к паролям на сайтах. Машине гораздо труднее угадать длинный, но запоминающийся пароль, чем короткую абракадабру с цифрами, заглавными буквами и спецсимволами. Это отлично показано известным комиксом xkcd ещё в 2011 году:
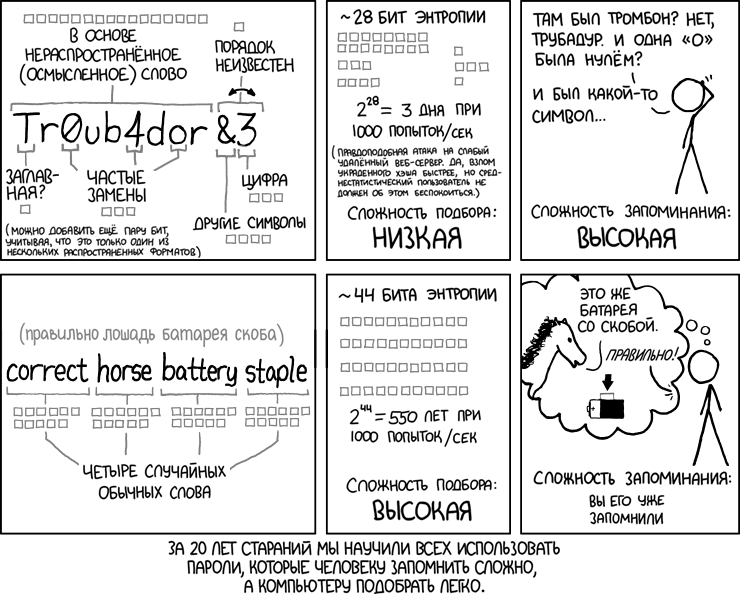
Автор древних стандартов NIST, которые требовали такие бессмысленные пароли, извинился за свою ошибку в 2017 году. Рекомендации отозвали. И вот на дворе 2025 год, а банки и другие учреждения, где должно быть полно экспертов по безопасности, до сих пор требуют вводить эту неэффективную и труднозапоминаемую ерунду.
Директора банков не хотят сделать вход в систему ненадёжным. Причина в другом. Возможно, надёжные пароли не особо влияют на прибыль (ведь у других банков всё так же плохо). Или директора не знают, кому верить в вопросах кибербезопасности. Конечно, вы-то знаете — нужно просто послушать любого гика, который читает xkcd и решал задачи на энтропию. Но директора не знают, что надо слушать вас, а не дорогого консультанта. А консультанты, видимо, не считают банковские пароли важной проблемой.
Такую же упорную некомпетентность можно найти: в системах торможения поездов, у известных производителей замков, выпускающих полный хлам, и у производителей сетевых устройств с легко взламываемыми заводскими паролями. И никакого хитрого заговора. Никакой тайной причины. Организации просто-напросто лажают.
Наличие в штате технических экспертов не означает, что их квалификации достаточно. Или что к ним прислушиваются в важных вопросах. Нужные знания могут где-то существовать. Но компаниям бывает трудно распознать и применить их.
Компании в экосистеме ИИ так и не показали миру достойного плана. Всё, что есть — либо смутные надежды и рекламные трюки, либо технически слабые идеи, которые рассыпаются при первом же вопросе. Мы не верим, что за кулисами скрывается тайная компетентность. Это как с банковскими требованиями к паролям, с тормозами поездов и с плохими замками.
(И правда, ИИ-компании явно некомпетентны в компьютерной безопасности. Например, в 2025 году OpenAI выпустила инструменты, позволяющие «агентам» ChatGPT работать с почтой пользователя. И почти сразу нашлись способы заставить ChatGPT выдать чужую переписку).
Кажется, что компания некомпетентна в не сильно влияющей на прибыль сфере? Скорее всего, так оно есть.