Nanotechnology and Protein Synthesis
Human intelligence has given us many advantages over other species. One of the most consequential, however, has been our ability to invent new technologies. If developers race ahead and build smarter-than-human AI, then we can similarly expect a great deal of AI’s power to come from its ability to advance scientific and technological frontiers. But what, concretely, does this look like? What not-yet-invented technologies are waiting for discovery?
This is a hard question to answer in any generality. A scientist in 1850 would have a very hard time guessing many of the inventions of the next hundred years.
However, they wouldn’t be totally helpless. Scientists have predicted many inventions decades or centuries before they were built, in cases where a technology could be reasoned about technically before engineers could put all the pieces in place.*
One of the more impactful technological frontiers we believe AI is likely to explore is the development of extremely small tools and machines. Below, we’ll go into some detail on this topic and the basic reasoning behind it.
The Example of Biology
Every cell of every organism in nature contains an enormous variety of intricate machinery.
“Machinery” here isn’t just a metaphor. The machines in question are small, so they work a bit differently than the machines in your daily life. But many large-scale machines have analogs within our bodies. ATP synthase generates power in the body in a similar way to a water wheel, using a flow of protons to spin a literal rotor.†
The bacterial flagellum functions similarly to the propeller of a boat, complete with an entire working motor that spins the flagellum to propel the bacterium through liquids:
Another example, which we mentioned in the book, is kinesin — a tiny protein that functions like a cargo robot. Kinesins “walk” down self-assembling fibers that traverse neurons, hauling neurotransmitters to their destination.
The smaller a machine is, the faster it can generally operate; and machines as small as molecules operate very quickly. Kinesins take as many as 200 steps per second, moving forward with one “foot” while the other foot holds fast to the microtubule it’s on.‡
One of the technological frontiers smarter-than-human AI may explore is building, designing, or repurposing machines at this very small scale. This kind of technology might get classified as “biotechnology,” “nanotechnology,” or something in between, depending on factors like scale, how closely a design matches existing structures in biology, and whether it’s “wet” (dependent on water, like the machinery in living cells) or “dry” (capable of operating in the open air).
Thinking of biological organisms as marvels of nano-scale engineering can help inform guesses about what smarter-than-human AIs are likely to be able to achieve with science and technology more advanced than anything we possess today.
(There is a separate question of how long it would take to invent and mature such technology. For more on that topic, see the discussion in Chapter 1 of the book about how machine superintelligences would likely be able to think at least 10,000 times faster than humans on existing computer hardware. See also our extended discussion on how AIs would have to spend some time running physical tests and experiments, but the overall slowdown probably would not be much hindrance to a superintelligence.)
Looking at the feats of human engineers today, it may seem to strain credulity that e.g. a superhumanly capable AI running a biolab could ever build microscopic factories that use sunlight to replicate themselves over and over. It might seem even more fantastical to imagine general-purpose micro-factories — factories that can accept instructions to build just about any machine out of the available resources.
But machines like that aren’t just possible; they already exist. Algae are micron-wide, solar-powered, self-replicating factories that can double in population size in less than a day. And algae contain ribosomes, which are biology’s version of a universal 3D printer or a universal factory assembly line (universal when it comes to the building blocks of life, at least).
Given the right set of instructions (encoded in messenger RNA), ribosomes will print out arbitrary structures that can be assembled from proteins. This universality underpins the enormous complexity and variety of the biological world — all of the diversity of life on Earth is ultimately assembled by these universal factories, which can be found essentially unchanged in everything from porcupines to fruit flies to bacteria.
Ribosomes can even be used to assemble structures that are not themselves made of protein by using proteins as an intermediary. An example of a non-protein structure that ribosomes can build in this fashion is bone. Ribosomes produce proteins that fold up into weakly bound enzymes that catalyze some calcium and phosphorus into special reactants. These reactants then form a collagen matrix that shepherds the calcium and phosphorus into place to turn it into hard, crystalline bone.
Nature provides an existence proof that some truly extraordinary physical machines are possible, for entities clever enough to use ribosomes in ways that humans haven’t — or entities that use ribosomes to build their own improved analogs of ribosomes.
But the structures we see in the biological world only set a lower bound for what’s possible. Biological organisms are nowhere near the theoretical limits of energy efficiency and material strength, and they may be relatively easy to improve upon for reasoners that are much smarter than humans.
Plenty of Room at the Bottom
If it seems strange to use natural phenomena as evidence of what future technologies are likely to be feasible, note that this is a common pattern in the history of science. Birds could fly, so inventors spent centuries trying to build flying machines.
Richard Feynman, a pioneering physicist, demonstrated the power of this approach in a 1959 lecture titled “There’s Plenty of Room at the Bottom.” In the lecture, Feynman does calculations on what kinds of interesting things could be done with miniaturization.
Today, Feynman’s observations come off as remarkably prescient. Feynman remarks on how computers could probably do much more if they contained more elements, but that the obstacle to this is how large computers would then need to be. They must be miniaturized!
Feynman calculates that it would take around one petabit (1,000,000,000,000,000 bits) to store all of the books written by humanity:
For each bit I allow 100 atoms. And it turns out that all of the information that man has carefully accumulated in all the books in the world can be written in this form in a cube of material one two-hundredth of an inch wide — which is the barest piece of dust that can be made out by the human eye. So there is plenty of room at the bottom! Don’t tell me about microfilm!
Even today, we haven’t quite achieved that! The actual storage element inside a 2-terabyte microSD card is still 0.6 millimeters per side. For reference, 1/200 of an inch would be 0.125 mm per side. And the SD card holds merely 17.6 trillion bits, which is only 1/57 of what Feynman calculated we’d need to store all of humanity’s knowledge in 1959.
Perhaps Feynman was mistaken about the ultimate limits of engineering in a practical sense? Further gains in computing miniaturization have been slowing down quite a lot, of late. To say that something is physically possible is no proof that engineers will be able to do it.
And coming within three orders of magnitude of what would one day be achieved could be seen as quite a predictive feat for Feynman. Feynman gave his lecture six years before Gordon Moore first floated the idea we now call “Moore’s Law.” People were not accustomed to thinking of miniaturization as an inexorable law on a graph. We’re not aware of anyone else in Feynman’s day who speculated that there might one day exist a device whose storage element, the size of a grain of sand, could hold ten million times as much information as the largest vacuum tube computers of the 1950s.
But in fact, Feynman wasn’t mistaken. And Feynman already knew at the time that his estimate was a safe one:
This fact — that enormous amounts of information can be carried in an exceedingly small space — is, of course, well known to the biologists […] all this information is contained in a very tiny fraction of the cell in the form of long-chain DNA molecules in which approximately fifty atoms are used for one bit of information about the cell.
Modern computers haven’t yet been miniaturized to the scale of DNA, but in sixty years, we’ve come remarkably close. The transistor gates in high-end commercial chips are now less than a hundred atoms across, built with technology that can add layers of material a single atom thick.
Anchoring to natural analogs and back-of-the-envelope physics calculations turned out to be a uniquely strong guide to what would be achieved in the coming decades. And technological trajectories like these can go much faster when AIs are doing the requisite science and engineering work.
Outdoing Biology
Why can’t flesh be as strong as steel?
It’s all the same atoms, after all, deep down. Metallic bonds between iron atoms are hard, but so are the covalent bonds between carbon atoms in diamond; why didn’t we evolve to have diamond chainmail running through our skin, helping us survive to reproductive age?
For that matter, if iron is so strong, why wouldn’t organisms evolve to eat iron ore and grow iron-plated hides — if human engineers can do that, why didn’t nature do it first?
Perhaps there’s some situational reason iron-plated hides in particular aren’t a great idea.
But if not that, why not something else?
The big overarching question here is: Why is nature far from the bounds of physical possibility — as calculated from physics or demonstrated by human engineering? Is there a deep and general answer, not just a narrow and shallow one?
We’ve noted that Feynman was able to use structures in biology to set lower bounds on what ought to be possible with greater scientific knowledge. But in many cases, human technology has already surpassed biology. Why is that possible, when evolution has had billions of years to upgrade plants and animals? Understanding this general phenomenon can help shed light on why nanotechnology is likely to be able to go far beyond what we can already see in nature today.
We can imagine finding ourselves in a world where redwoods stand at least half as tall as the tallest buildings. We can imagine a world where the skin of the toughest animals is at least half as hard as the hardest observed materials. Why don’t we find ourselves in a world like that, where nature has pressed itself up against physical limits after a few billion years of evolution?
This is a deep enough question that we cannot briefly summarize all that is known. But the rough summary is that natural selection has a hard time accessing some parts of design space, including many parts that are a lot easier to reach if you’re a human engineer.
The three main factors we see contributing to this are:
- Natural selection has limited selection pressure to work with, and needs hundreds of generations to promote a new mutation to universality. If a biological feature isn’t very, very ancient, then its design often looks time-constrained, rushed out the door.
- Everything built by natural selection started as an accidental error in some previous design — a mutation. Evolution has a harder time exploring parts of design space that are distant from what currently exists in organisms. It’s difficult for evolution to leap across gaps.
- Natural selection has a hard time building new things, or fixing problems, that would require simultaneous changes rather than sequential changes. This sharply limits what designs evolution can access and gives current designs in biology their patchy, hacky, hugely tangled look by human engineering standards. For instance, you can get a sense for the complexity of the (known parts of) the human metabolism using the Roche Biochemical Pathways Wall Chart.
Or, for a simpler example of evolution’s messiness, consider the eye. Vertebrate eyes happened to evolve with their nerves (2 in the image below) sitting on top of the light-detecting cells (1). These nerves need to exit the eye through a hole in the back (3), and since this spot has a hole, it must lack light-detecting cells. This creates a blind spot (4) for all vertebrates, including humans, forcing the brain to do clever tricks to “fill in” the hole (e.g., with information from the other eye).
/images/image2.png "\"Evolution eye\" by C. C. MacDuff, CC BY-SA 3.0.")
Octopuses evolved eyes independently, and, by chance, they happened to evolve the more sensible design — nerves go behind the light-detecting cells. This lets these cables exit the eye without creating any blind spot at all.
Or consider the recurrent laryngeal nerve of the giraffe, which needs to connect the giraffe’s throat to its brain so that it can operate the larynx. Rather than taking the direct path, this nerve travels from the throat, all the way down the full length of the giraffe’s neck, awkwardly loops around the giraffe’s aorta, travels all the way back up the neck to return to where it started, and then connects to the brain.
The result is a nerve that’s fifteen feet long (the black loop in the image below), resulting in signals taking ten to twenty times longer than necessary to travel between the giraffe’s brain and its throat.
/images/image3.png "by Vladamir V. Medeyko, CC BY-SA 2.0.")
In fish, this design made sense because their version of a laryngeal nerve connected the brain to the gills — a straight shot. Take the same design and give the animal a neck, however, and keep lengthening the neck without ever redoing the wiring from scratch, and you get some very inefficient designs. Survivable, but inefficient.
Evolution produces marvelous designs, given enough time. But humans and AIs can come up with a much more varied and flexible range of designs, and we can do so very quickly.
The first multicellular organisms with differentiated and specialized cells seem to have evolved around 800 million years ago. In human terms, that feels like an eternity. But evolution works far more slowly than human civilization.
A newly mutated gene conveying a 3 percent reproductive fitness advantage — relatively huge, for a mutation! — will on average take 768 generations to spread through a population of 100,000 interbreeding organisms. If the population size is 1,000,000 (the estimated human population in hunter-gatherer times), it will take 2,763 generations. And the mutation’s probability of spreading to fixation at all, rather than randomly dying out, is only 6 percent.
In population genetics, the rule of thumb is “one mutation, one death.” If DNA copying errors introduce ten copies of a deleterious mutation in each new generation, then ten bearers of that mutation must die or fail to reproduce, per generation, in order to counterbalance the pressure of simple genetic noise.
This is not quite as bad as it sounds, as a cost of maintaining genetic information. In a sexually reproducing species, you can end up with one person (or one embryo) carrying lots of deleterious mutations who dies — or fails to reproduce, or miscarries — and that can remove more than one mutated-gene-instance at a time. But this constraint is still the standard explanation for why humans have lost so many different useful adaptations that show up in chimpanzees and other primates. While natural selection was busy selecting for increased primate intelligence (for example), it had less room to preserve all of the subtle olfactory genes that allow for a richer sense of smell.. The relevant olfactory genes were useful for survival, but they weren’t quite useful enough to stick around while evolution’s “attention” was elsewhere.
Most giraffes do not die as a result of their comically long laryngeal nerve. Maybe some giraffes manage to choke on twigs that would have survived if their brain were able to respond faster — but this is probably not very common. So it is simply not that high of a priority for natural selection, which only has so much optimization pressure to spread around. The slapdash giraffe design mostly works, it gets shoved out the door, and it’s done.
Realistically, evolution can’t refactor its designs or start from scratch; it can only make tweaks. But even if a better design were available, refactoring these weird extra complications and cleaning up the design debt isn’t natural selection’s priority.
And because natural selection never thinks ahead, it doesn’t become the priority even if there are some other big upgrades to the giraffe that you could unlock with a less wacky nervous system layout. Natural selection doesn’t plan. It is simply the frozen history of which genes and organisms have already in practice reproduced.
Being able to spot a bad design doesn’t necessarily mean that you can build a better giraffe yourself. But humans have made a remarkable amount of progress in a very short time when it comes to spinning up hundreds of thousands of machines that do things nature can’t. We expect this to hold with even more force if and when AIs become better than humans at design and are able to do the same cognitive work hundreds of thousands of times faster.
Natural selection’s ability to “design” a better giraffe is stymied by the fact that it operates through mutation and recombination. It has a hard time accessing any part of design space that can’t be reached by a series of single mutations, which must all be individually and separately advantageous, or by combining mutations which were all individually advantageous enough to be present in a large fraction of the gene pool before they combined.
A gene complex made of five genes, each independently at 10 percent prevalence in the population, has only a 1-in-100,000 chance of assembling inside each organism. And a gene complex that’s a huge advantage, but only 1-in-100,000 times, has almost no chance of evolving to fixation.
This doesn’t mean natural selection can’t make complex machines — it just means that its road to complex machinery has to go through incrementally advantageous steps. To reroute the giraffe nerve would require a handful of simultaneous changes to the giraffe genome, and each of those changes would be individually unhelpful without the other changes. So giraffe anatomy stays the way it is.
The wonder of evolution is not how quickly it works; its sample complexity is far higher than that of a human engineer doing case studies. The wonder of natural selection is not the elegant simplicity of its designs; one glance at a pathway diagram of any biochemical process would cure that misapprehension. The wonder of natural selection is not its robust error-correction covering every pathway that might go wrong; now that we’re dying less often to starvation and injury, most of modern medicine is treating pieces of human biology that randomly blow up in the absence of external trauma.
The wonder of evolution is that — as a purely accidental search process — evolution works at all.
The Weakness of Protein
This brings us to another way that technology can likely improve on biology.
Far below the level of flesh, invisible to the naked eye, are the cells. Far below the level of cells are the proteins.
Proteins, as they fold up, are mostly held together by the molecular equivalent of static cling — van der Waals forces tens or hundreds of times weaker than metallic bonds like iron, or even covalent bonds like diamond.
Why does biology use such weak material as its basic building block? Because stronger material would have been harder for evolution to work with. (And if you make it too hard to evolve things, then you never evolve the sort of people who ask that sort of question.)
Proteins fold up under relatively light molecular forces and are bound into those shapes mostly by static cling. This is a major reason why natural selection has a rich neighborhood structure of possibilities to explore: Random mutations can repeatedly tweak a protein and end up stumbling into a new design that does mostly the same thing, but slightly better.
If organisms were instead made of molecules held together by tight bonds, then changing one of the components would be less likely to produce an interestingly different (and potentially useful) new structure. It could still happen sometimes! But it would happen significantly less often. And if you’re the type of designer that takes two billion years to invent cell colonies and another billion years to invent differentiated cell types, “it happens less often” means that the nearest star swells up and swallows your planet before you get that far.
Every protein is there because of a copying error from some predecessor protein. The predecessor protein wasn’t tightly held together by many strong bonds because that would have been harder to evolve from. So the latest new protein probably doesn’t have many strong bonds either.
Biochemistry does sometimes figure out strong bonds. We noted the example of bone earlier. Another example occurs in plants. Plants have evolved proteins that fold up into enzymes, which catalyze the synthesis of molecular building blocks, which get oxidized into a heavily covalently crosslinked polymer: lignin, the building block of wood.§
But those are special cases, and natural selection does not have a lot of “attention” to spend on engineering a lot of cases like that.
It is not foreign to the nature of carbon atoms and other common organic elements that they could ever be strong. It just takes a lot more work to evolve. Natural selection doesn’t have the time to do that everywhere — only for a few rare special cases patched into the rest of the anatomy, like bone, like the lignin in wood, or like the keratin in nails and claws.
If you go in with the right keywords, you can interrogate, say, ChatGPT-o1 — by the time you read this, LLMs of equivalent strength will probably be free — and ask it about the individual bond strengths of the carbon-carbon bonds in diamond, or the iron-iron bonds in plain iron metal, or the covalent polymer bonds in lignin, or the disulfide bonds in keratin, or the ionic bonds in bone. You can ask it how all these relate to the structural strengths of the larger material. (In 2023 you should not have tried this because GPT-4 would get all the math wrong, but as we write this paragraph in 2024, o1 seems better.)
You would learn that the exact bond strength between two carbon atoms is on the order of half an attojoule, as is the bond strength between two iron atoms, and the sulfur-sulfur crosslink in keratin is only slightly less (0.4 attojoules), and likewise the polymerized covalent bonds in the lignin in wood.
But the static cling forces that fold up proteins are, depending on how you look at it, at best ten times weaker, and potentially hundreds or thousands of times weaker than that.
And even when plants catalyze substances like lignin, the crosslinks there tend to be sparser than the carbon-carbon bonds in diamond. The difference between the gigaPascal strength of diamond, versus the megaPascal strength of wood, is more about the density and regularity of bonds in diamond, not the diamond bonds being individually stronger.¶
Due to evolution’s limitations as a designer, and protein’s limitations as a construction material, life operates under constraints that human designers and AIs can bypass. Birds are wonders of engineering, but man-made flying machines can carry cargo ten thousand times as heavy at more than ten times the flight speed of the fastest and strongest birds. Biological neurons are wonders of engineering, but man-made transistors switch on and off tens of millions of times faster than the fastest neurons. And the technology we have today is still only scratching the surface of what’s achievable.
Freitas and Red Blood Cells
We’ve said that biology isn’t anywhere near the limit of what’s physically possible. So what is near the limit?
To illustrate some good ways of thinking about this question, we can consider red blood cells.
For the last 1.5 billion years, in everything from humans to lizards, oxygen has been carried around in multicellular life by hemoglobin. Hemoglobin is a protein made up of 574 amino acids, plus four specially made heme groups to hold a special iron molecule. A human red blood cell contains around 280 million hemoglobin molecules and is around seven microns long. Three million of them could fit on the head of a pin, and you’ve got around 30 trillion of them in your body.
How close are red blood cells to the limits of what you could do in principle, when it comes to carrying oxygen?
Rob Freitas, author of Nanomedicine, did a moderately detailed workup in 1998 of a theoretical design for an artificial red blood cell using covalently bonded materials. The cell was designed to be a single micron in diameter to more easily travel through clogged arteries.
Rather than just considering a different way to store oxygen molecules, Freitas considered how to replace the entire red blood cell. Freitas drew on previous analyses to consider the need also to get glucose out of the blood medium and turn that glucose into energy to power the artificial cell. He considered cell-sized sensors and tiny onboard computers made of solid rods clicking into other solid rods to do simple computations. He considered whether the artificial cell would settle out of suspension in liquid faster than current red blood cells.
Biocompatibility can be a huge issue for anything that goes inside a human body, but diamond surfaces are inert enough that diamond-like film coatings are in use for some medical devices that go inside a human body. At the level of theoretical possibility Freitas was considering, this means he just says the artificial cell’s surface can look like a diamond and therefore be biocompatible.
The centerpiece of the artificial red blood cell was Freitas’s calculation that a micron-scale single-crystal corundum or diamond pressure vessel would conservatively tolerate 100,000 atmospheres of pressure. Allowing a comfortable 100-fold safety margin, and packing in molecules at only 1,000 atmospheres, this would allow the artificial red blood cells to deliver 236 times more oxygen to tissue than red blood cells per unit of volume, and to store a similar amount of carbon dioxide to buffer the other side of respiration. Roughly: You could hold your breath for four hours.
Now, actually building artificial blood cells like that is another matter entirely. That is why this particular medical treatment is not already available at your local doctor’s office.
A 1-kilogram sphere of solid flawless diamond is an easy molecule to describe on paper, but synthesizing it is harder. What Freitas does help us do is make more informed guesses about how far from theoretical limits current biology is in this domain.‖ Biology is impressive, but far from optimal.
It’s plausible that, for any number of reasons, Freitas’s exact design wouldn’t work, and it’s very likely that it wouldn’t be optimal. An initial idea for an extremely novel complex design is almost guaranteed to run into issues somewhere.
But in expressing skepticism that Freitas’s exact proposal would work, we are not claiming that no red-blood-cell alternative could ever deliver oxygen hundreds of times more efficiently than biological red blood cells.
Engineering is about finding some way to make something work. Even if a thousand paths to building something fail, it only takes one success for the whole endeavor to succeed. The existence of myriad unworkable aircraft designs in the seventeenth century and earlier didn’t mean functioning airplanes were impossible — just difficult to locate in the space of all possible designs.
This is why technological skeptics, while often correct that technologies are further off in the future than the most bright-eyed optimists believe, have tended to be wrong in their claims that certain technological feats will never be achieved. When the feat is a concrete task in the world, when we’re agnostic to how the feat is achieved, and when the feat is known to be permitted by the laws of physics, history suggests that there is often some way to succeed, even if the path isn’t initially obvious.
Or, in the words of the author and inventor Arthur C. Clarke:
When a distinguished but elderly scientist states that something is possible, he is almost certainly right. When he states that something is impossible, he is very probably wrong.
Nanosystems
To recap:
- The biological world is built out of an incredible variety of molecular machines.
- Looking at biology can teach us about what microscopic feats are possible, technologically.
- But biology is a conservative bound on what’s possible; it is not near the limits of possibility. Evolution is a very limited designer, and protein isn’t the greatest construction material.
Eric Drexler’s Nanosystems (1992) is the classic book exploring the question of which small-scale engineering feats are possible. Nanosystems helped kick off the nanomaterials revolution of the 1990s and sparked a fair amount of controversy as scientists debated Drexler’s arguments. You can find a full online copy of Nanosystems here.
Nanosystems is an in-depth and wide-ranging text, and a surprisingly accessible one given its technical subject matter. A key contribution of the book was to explore the implications of building small-scale structures in a novel way.
One way to build very small things is via chemical reactions: smashing molecules together under particular conditions (such as extreme heat) to break apart molecules and cause atoms to join into new molecules.
This is a powerful approach in its own right, and is the method humanity uses to make materials like plastics, steels, and ceramics, but it pales in comparison to what can be built by other methods. Making materials out of chemical reactions is a little like building LEGO structures by taking bags full of LEGO bricks and shaking them hard. It’s possible to build some things that way, but the set of things you can build is limited, and there’s a lot of waste.
Protein synthesis is like using your hands to build large LEGO structures out of smaller, pre-constructed LEGO sets. There’s room for a lot more precision because you can place each pre-constructed set precisely where you want it, but it’s still a bit weird and awkward because you’re working with pre-constructed sets. This is what ribosomes do in the body: stringing together chains of amino acids to form proteins, which are then used to perform a variety of tasks in the body.
Insulin, hemoglobin, and ATP synthase in the human body are all examples of protein complexes built out of multiple protein chains stuck together: two protein chains in the case of insulin, four for hemoglobin, and twenty-nine for ATP synthase.
The building blocks of proteins — amino acids — are molecules, typically made up of ten to twenty-five atoms. As construction materials, amino acids have a lot going for them:
- Each amino acid has a backbone that attaches to a (potentially long) side-chain of carbon, hydrogen, oxygen, nitrogen, and sulfur atoms. Hundreds of different side-chains are possible, which will then behave in different ways, making amino acids very flexible tools.
- An amino acid’s backbone, like a LEGO piece, can be stuck to the backbone of another amino acid. This can be repeated over and over; the typical protein is made up of hundreds of amino acids stuck together. This makes amino acids even more flexible as tools (or as building blocks of tools). The complexity of proteins also means that proteins can often undergo small tweaks (via DNA mutations) without radically changing and becoming entirely useless — which in turn makes it easier for new proteins to evolve.
- Because proteins are made of linear chains of amino acids, you can uniquely specify a protein by just listing its amino acids in order. DNA takes advantage of this by using an “alphabet” of four letters (nucleotides) to form three-letter “words” (codons, each representing a different amino acid), which can then be strung into a linear “sentence” (a protein made up of that exact sequence of amino acids). (Video illustration of DNA.)
- As shown in the Miller-Urey experiment, amino acids can spontaneously form in the absence of life, from simple chemical reactions. This creates a path for life (and the precursors of ribosomes and protein synthesis) to develop in the first place.
Bodies get the twenty-or-so amino acids they need for protein synthesis from food, or by synthesizing them in the body, or by harvesting amino acids from past proteins. Ribosomes receive instructions from DNA that essentially say “use this amino acid, then this other amino acid, then this other amino acid, …, then stop.” The amino acids are then carried (by small molecular machines called transfer RNA) to the ribosome, which builds the protein piece by piece.
Notably, the above list consists of features that are highly valuable for evolution, but much less necessary for deliberate engineering. Evolution needs a relatively simple but flexible chemical structure that can be produced by common chemical reactions. A human or artificial designer is free to choose from a variety of unrelated molecules, rather than needing all of them to be closely related. They’re also free to use building blocks that rarely arise in nature and to assemble these building blocks in complex top-down ways.
This provides part of the impetus for exploring a third way to build very small things: mechanosynthesis, in which structures are built by directly moving atoms to the correct location, potentially using a ribosome-like machine to take in instructions and then assemble things far more varied than just different proteins. In the LEGO analogy, mechanosynthesis is like finally being able to work with individual LEGO pieces and place each one exactly where you want it.
Nanosystems explores what kinds of new machines might be possible with mechanosynthesis. An example of the kind of design Drexler explores is a planetary gear scaled down to only around 3,500 atoms in size:#
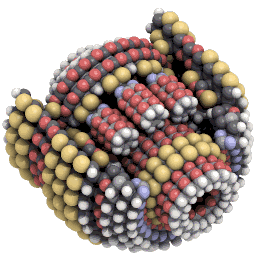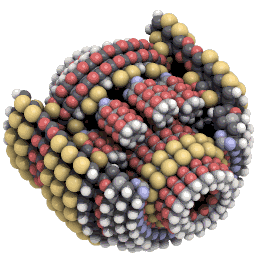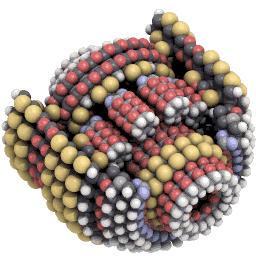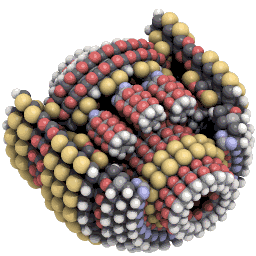
Hemoglobin is made of around 10,000 atoms, not that far off from Drexler’s gear. And some proteins get away with being a lot simpler. Insulin is made of only fifty-one amino acids, or around 800 atoms in total.
Drexler’s designs, however, are a big step down in scale from the more complicated machines we see in the body. Ribosomes and ATP synthase, for example, are made of more than 100,000 atoms, and the motor of a bacterial flagellum has over a million atoms.
Nanosystems still doesn’t attempt to explore the limits of what’s technologically possible. But by focusing on cases that are relatively easy to analyze today, it does show that mechanosynthesis would allow for technology that exceeds what we see in the biological world today.
The calculations in Nanosystems are intentionally conservative ones. Drexler, for example, considers computers built out of literal diamond rods moving around — not because this was the final limit of technology, but because in 1992 it was easier to analyze than electricity-based computation. This, in turn, helped inspire Freitas’s blood cell analysis. Four years later, Eric Drexler and Ralph Merkle (more widely known as the inventor of cryptographic hashing and co-inventor of public-key cryptography) tried to analyze a system slightly closer to the limits of possibility for reversible computing, and calculated 10,000 times less heat dissipated per operation than Nanosystems had estimated — though the new estimate was based on a less carefully conservative analysis.
Elsewhere in Nanosystems, there is a rough sketch for a six-degrees-of-freedom manipulator arm that would have required millions of atoms. A later attempt to sketch a machine like this atom by atom turned out to require only 2,596 atoms.
There are large engineering challenges involved in building atomically precise structures at the scale Drexler is talking about. One major challenge is that building atomically precise structures requires wielding incredibly small and precise manipulators. The existence of ribosomes, however, provides a potential avenue of attack.
While ribosomes can only build proteins, proteins can catalyze and drag around reactants that are not themselves amino acids (like bone and wood). Ribosomes are powerful and general factories, and the products of ribosomes can be used to bootstrap to smaller and more precise tools, including tools that more directly build smaller devices using stronger materials.
Whether directly or indirectly, it’s almost certainly possible for genomes to produce tiny actuators that can manipulate individual atoms to build a variety of things that aren’t made out of proteins. And importantly, this is not the sort of mechanism that natural selection is liable to stumble its way into, even if it’s relatively easy to build, because the manipulator arm isn’t useful until it’s complete.
Evolution builds complex structures that are useful at every step along the way. Even a lot of relatively simple designs are available to intelligent engineers, but not to evolution. Freely rotating wheels, for example, are an incredibly simple invention that has a huge variety of applications. In spite of this, freely rotating wheels appear to have evolved only three times in the entire history of life on Earth: in ATP synthase and the bacterial flagellum that we discussed earlier, and in the archaeal flagellum, which appears to have evolved independently.**
In spite of the conservative methods used in the book, the technological lower bound set by Nanosystems is very high in absolute terms. A superintelligence with the kind of technology Drexler describes would be able to produce tiny self-replicating ribosome-like factories that double in population size every hour — some organisms replicate even faster, but Drexler did calculations conservatively — and that can group together to build larger macroscopic structures, such as power plants.
Nanosystems like the ones Drexler describes can self-replicate using sunlight and air as raw materials, making it possible to expand very quickly and reliably. The reason this can work is the same reason trees are able to assemble bulk construction materials largely out of thin air by stripping carbon from the air and sequestering it as wood. Although we think of air as “empty space,” the carbon, hydrogen, oxygen, and nitrogen in the air are building materials that can be rearranged into solid materials and put to a variety of ends.
Self-replicators in the vein of Nanosystems, being made of materials like iron or diamond rather than protein, could chew through biological cells in much the same way a lawnmower cuts through grass.
They could cheaply synthesize something like botulinum toxin, the protein responsible for botulism. A millionth of a gram of botulinum toxin — twenty thousand times smaller than a single grain of rice — is a lethal dose. Carefully designed replicators could propagate invisibly through the open air until at least one had likely been inhaled by almost every human (that hadn’t e.g. spent the last month entirely on a submarine), at which point the devices could (on a timer) simultaneously release a tiny dose of toxin, immediately and simultaneously killing almost every human.
Or AI-constructed nanosystems could wipe humans out incidentally, in the course of harvesting and repurposing the Earth’s resources. A paper by Freitas calculates that micro-diameter machines, relying only on sunlight for power and the air’s hydrogen, carbon, oxygen, and nitrogen for raw materials, could be designed to reproduce so quickly that they black out the sky in less than three days, while also consuming the entire biosphere.†† Consequently, if the first AI to achieve technology like this has a lead time of mere months, it could plausibly use that lead time to destroy all competitors (be they human or AI). This is a technology that confers a permanent and decisive strategic advantage to the first wielder of that technology.
To say that Drexlerian nanotechnology is achievable in physical principle doesn’t necessarily mean that early smarter-than-human AIs could actually build technology that nears those physical limits. Our best guess is that it’s within the range of things an artificial superintelligence could figure out, because figuring these sorts of engineering tasks out seems mostly like a cognitive challenge (that can be solved by thinking) and we don’t expect the experimentation and testing phase has to be all that long.
Even if this guess of ours is correct, it’s no guarantee that a superintelligence’s first move would involve using nanotechnology to build its own infrastructure and take control of the world’s resources. For all we know, it would develop techniques and technologies that achieved its ends even faster and more efficiently.
But if smarter-than-human AI is in fact able to build systems that are to cells what airplanes are to birds, and proliferate its own infrastructure across the face of the Earth, then whatever it did wind up doing would be at least that decisive.
The point of all this analysis is to argue that human technology is far from the limits of possibility. There exists a wide variety of important technologies that would likely take humanity decades, centuries, or millennia to figure out, and which artificial superintelligences would be able to do quickly.
In short, Nanotechnology illustrates that a superintelligence with a small bit of lead time could probably find technological solutions for taking over the planet.
The most likely outcome of building a superintelligence is that it figures out some technology at least as powerful as nanotech, and then humanity just loses.
This guess isn’t critical to the argument we make in the book. Humanity would lose to a superintelligence even if the world didn’t contain a “win immediately” technology such as nanotech. So we don’t go into all this analysis in the book proper.
In Part II, we deliberately focus on a takeover scenario that doesn’t assume the AI has anything like a general-purpose ability to do atomically precise manufacturing, either via ribosomes or via mechanosynthesis. A superintelligence doesn’t need an utterly overwhelming technological advantage to win control over the future, and so we don’t focus too much on the possibility in the book.
But it also seems worth pointing out that it probably will have an utterly overwhelming technological advantage.
* Perhaps the most notable example is the case of computers, with substantial theory worked out by the likes of Charles Babbage, Ada Lovelace, Alan Turing, Alonzo Church, and others
† Visualization by Roman Balabin, CC BY-SA 4.0.
‡ Chapter 15 of Eric Drexler’s Nanosystems collects more examples of technologies with analogs in the biological world.
§ Even inside proteins, some covalent bonds are possible. Two cysteine amino acids can form a covalent sulfur-to-sulfur bond between themselves, where two proteins touch or where a folded-up protein touches itself. That’s how your fingernails manage to be harder than skin, or why hair is stronger than the same diameter and length of muscle: lots of sulfur-sulfur bonds in a protein that’s 14 percent cysteine by mass. This is also why hair smells awful and sulfurous when burned.
Mostly, however, natural selection builds things out of proteins, which have covalently linked backbones, which then fold up into complicated shapes because of relatively very weak static-cling pulls. And proteins usually bind to other proteins the same weak way.
Mostly, the covalent bonds are scattered scarcely, where they exist at all. Adding 0.1 percent covalent bonds to a structure doesn’t make it as strong as a diamond molecule where every carbon atom is covalently bound to four other carbon atoms in a rigid geometric structure.
¶ Diamond is also more fragile. The extreme crystalline regularity of diamond’s bonds means that it breaks all at once. Iron is less fragile because each huge iron nucleus lives in a cloud of electrons and can be nudged within that cloud without breaking.
(Sparse covalent bonds do mean that materials can be nudged more easily without breaking, relative to their strength. But bone still breaks, and wood is less hard than steel. Which is to say: Yes, there are tradeoffs, but natural selection is nowhere near the edge of those tradeoffs.)
‖ Though Freitas was working under the added constraint that he needed his artificial red blood cells to play nicely with the rest of a human body’s systems. The cell would need to run off glucose found in bloodstreams, for example, rather than being able to recharge off of electricity. In that sense, Freitas’s estimates provide a more conservative lower bound than if he’d been able to upgrade other parts of the human body too, or start from scratch with a new organism or a robot.
# From the Nanorex website: “A section of the casing atoms have been hidden to expose the internal gearing assembly.”
** You can read long analyses online about why it wouldn’t be useful for biology to invent freely rotating wheels. An example of a common issue is: How do you use blood vessels to send blood to the wheel if it’s freely rotating? The blood vessels would end up all twisted up when the wheel moves!
The three known cases of wheel invention are at the molecular level, and so bypass these macroscopic anatomical issues. The biological wheels are macromolecules that are typically identical down an atomic level. There is no question of applying lubrication, polishing away grit, or sending in new cells to replace old damaged cells. Those three wheels and gears work because they are made of molecules rather than cells, folded up as protein complexes rather than grown into tissue matrices or deposited as chitin.
Similarly, you can read arguments online about how animals developing wheels for locomotion wouldn’t be that useful anyways, without paved roads. But the three known cases of molecular wheels are incredibly thermodynamically efficient and in extraordinarily vital positions to their organisms — you cannot make much of a case that ATP synthase is not a useful wheel to possess. Freely rotating wheels would have more potential uses in bodies (and in biochemistry) than just using them to replace feet.
For that matter: Some of the most dextrous modern robots, which can climb over rocks or snow or balance on one limb and do backflips, also have wheels added to the ends of their feet. Why wouldn’t they? It’s easy enough for a human engineer to stick wheels at the ends of legs. The main thing getting in the way isn’t that wheels are useless; it’s that it turns out to be hard to find an evolutionary pathway to achieve wheels, even though wheels are trivial from the perspective of a human designer.
†† At the time, Freitas interpreted his numbers as an upper bound on how quickly this process could occur, but this turned out to be wrong. Freitas’s analysis had assumed that the nanosystems’ mass would be dominated by radiation shielding, but this relied on a (false) assumption in Nanosystems: that a single radiation strike would knock out a nanosystem.
Drexler had made this assumption, like many others in Nanosystems, to be conservative: Assume that the problem is harder, and show that it’s solvable anyway. This may be appropriate in Nanosystems, but it means that Freitas’s paper isn’t conservative in its own estimate.
Because Freitas’s analysis combines numbers that are conservative in different directions, it doesn’t provide either a clear upper or lower bound on how long it would take replicators to consume the biosphere. It’s more like a middling estimate. Perhaps the actual physical limits on how fast the biosphere can be consumed starting from a single replicator is three hours; perhaps it’s thirty days. It’s almost surely not three years.
Notes
[1] Less than a day: Many algae strains have a doubling time of around ten to twenty hours; a recently developed strain doubles in just over two hours.
[2] longer than necessary: The giraffe’s recurrent laryngeal nerve takes the scenic route to the brain. In contrast, the giraffe’s superior laryngeal nerve takes the direct route and is therefore quite small and fast.
[3] far more slowly: The oldest definitive microfossil evidence of life is 3.5 billion years old, with more indirect evidence pointing at closer to 4 billion years. The earliest multi-cell colonies look to be 2 billion years old. The vast majority of all evolutionary history was spent churning through single-cell designs, and then single-cell designs that aggregated well, before — accidentally! evolution does not foresee! — stumbling over some new trick which pried open the “multicellular life” region of design space, containing all of the plants and all of the animals.
[4] probability of spreading: If a mutation’s fitness advantage is s << 1, and the population size is N, then the probability of the mutation spreading through the whole population (called “fixation”) is about 2s, and the time it takes the mutation to fully spread is about 2 ln(N) / s.
[5] artificial cell: Freitas’s works include diagrams of molecular sorting rotors that could pump specific molecules in and out of a diamond-sheathed artificial blood cell.