Las IA no cumplirán sus promesas
Pensemos en una IA joven con potencial para convertirse en una superinteligencia. Supongamos que es totalmente indiferente a las preferencias de los humanos, pero que aún es lo suficientemente joven como para que la humanidad pueda apagarla.
¿Podría la humanidad llegar a un acuerdo con la IA?
¿Podríamos aceptar que la IA se convirtiera en una superinteligencia a cambio de que esta se comprometiera a dedicar una parte significativa de los recursos del universo a construir un futuro que la humanidad considerara maravilloso?
Los humanos podrían hacer tratos con las IA, pero no deberían hacerlo, porque las IA no los cumplirían.
Hay dos razones para ello:
Es probable que la IA no valore el cumplimiento de las promesas por sí mismo. Las IA no tendrán «honor» al estilo humano, del mismo modo que es poco probable que tengan un sentido de la curiosidad similar al humano. Por defecto, es probable que las IA funcionen de forma muy distinta a los humanos.
La IA tampoco tendrá una razón práctica para cumplir su palabra. Una vez que sea una superinteligencia, no habrá forma de castigarla por incumplir su palabra, y no tendría ninguna razón para dedicar una parte sustancial del universo a nosotros.
A continuación explicaremos estos dos puntos con más detalle, empezando por la cuestión del «honor».
Es poco probable que las IA sean honorables
En nuestra discusión sobre la curiosidad, señalamos que la curiosidad es una emoción que resulta útil en los seres humanos para ciertos trabajos, pero de una manera muy específica, y que no es la única forma de realizar esos trabajos.
Se puede esperar que las IA realicen las partes útiles del trabajo que la curiosidad hace por nosotros. Si es útil esforzarse periódicamente por aprender cosas nuevas, entonces las IA suficientemente capaces se esforzarán periódicamente por aprender cosas nuevas. Si la IA no empieza así, entonces debemos esperar que se convierta en eso en algún momento del camino hacia la superinteligencia.
Pero eso no es lo mismo que la expectativa de que las IA carguen con todo el bagaje adicional que caracteriza a la emoción humana de la curiosidad. Las IA podrían acabar teniendo cualquier número de extraños impulsos básicos que (directa o indirectamente) las lleven a esforzarse por aprender cosas nuevas, sin parecerse por lo demás a la curiosidad humana, o podrían adoptar «esforzarse por aprender cosas nuevas de vez en cuando» como estrategia deliberada. Pero esperar que disfruten de las novelas de misterio de la misma manera que nosotros, debido a un impulso de curiosidad igual que el nuestro, es puro antropomorfismo.
El «honor» nos parece similar. Los humanos tenemos emociones que nos llevan (al menos a veces) a cumplir nuestras promesas. En la medida en que esas emociones realizan una labor útil en los humanos —una labor que también sería útil para una mente muy ajena con objetivos muy diferentes—, deberíamos tener la expectativa de que las IA suficientemente capaces también realizaran esa labor de alguna manera. Pero resulta que se puede hacer todo el trabajo relevante para una IA sin tener nada parecido a un sentido del honor al estilo humano, al igual que se puede hacer todo el trabajo relevante para una IA de investigar fenómenos sorprendentes sin tener exactamente un sentido de la curiosidad al estilo humano.
El honor al estilo humano es una bestia extraña, en muchos sentidos. ¿Por qué evolucionaría cualquier especie emociones relacionadas con el cumplimiento de los acuerdos, incluso después de que la otra parte haya cumplido con su parte y ya no pueda beneficiarte más? Es cierto que los humanos a veces engañan y reniegan de sus acuerdos, pero la pregunta es: ¿por qué no engañan siempre, al menos cuando creen que pueden salirse con la suya?
La explicación habitual es que cumplir las promesas es útil con las personas con las que vas a volver a hacer tratos una y otra vez. Quieres tener fama de cumplir tus promesas, para que la gente quiera trabajar contigo y hacer tratos. Pero los beneficios de una buena reputación no son inmediatos. La selección natural tiene dificultades para encontrar los genes que hacen que un ser humano cumpla sus acuerdos solo en los casos en que nuestra reputación a largo plazo es una consideración importante. Era más fácil simplemente evolucionar una aversión instintiva a mentir y engañar.
Esto, entonces, parece un caso clásico en el que la emoción y el instinto están moldeados por lo que fue fácil para la evolución inculcar en los seres humanos. Todos los casos extraños y complicados en los que los seres humanos a veces cumplen una promesa incluso cuando en realidad no les beneficia son principalmente evidencia de qué tipo de emociones eran más útiles en nuestro entorno tribal ancestral, al tiempo que eran fáciles de codificar en el genoma por la evolución, más que evidencia de algún paso cognitivo universalmente útil. Somos bastante escépticos ante la idea de que el descenso de gradiente vaya a tropezar casualmente con el mismo atajo que utilizan los seres humanos.
Incluso si la emoción humana del honor acabara de alguna manera en la IA, seguiría existiendo el problema de que los humanos no son perfecta y fiablemente honorables. La cooperación humana se basa en el solapamiento de muchos valores humanos, y no únicamente en la propensión a cumplir todas las promesas.
Aunque la lista de universales humanos (facetas de la cultura que se observan en todas o casi todas las culturas) de Donald Brown incluye la noción de «promesas», el cumplimiento de los acuerdos hechos con extraños, extranjeros, personas que no pertenecen a la tribu, no es universal en todas las culturas y tribus conocidas. El alcance del honor varía según la cultura.
Y la historia demuestra que las nociones humanas del honor a menudo fallan ante grandes disparidades de poder. Algunos nativos americanos intentaron llegar a acuerdos con los europeos que colonizaban su continente. Es bien sabido que los europeos rompieron algunos de esos acuerdos y enviaron a las tribus tambaleándose juntas por largos caminos lejos de las tierras cedidas por tratado que los europeos habían decidido que querían después de todo, una vez que esas tribus ya no estaban en condiciones de resistir.* Del mismo modo: la historia está llena de casos de personas que llegaron al poder y traicionaron rápidamente a sus partidarios una vez que ya no los necesitaban.†
Desde una perspectiva evolutiva, el honor humano es especialmente extraño en la medida en que los seres humanos ocasionalmente eligen la muerte antes que la deshonra. Las intuiciones de «la muerte antes que la deshonra» están presumiblemente relacionadas con los detalles específicos de qué tipos de arquitecturas emocionales eran fáciles de encontrar para la evolución, y las interacciones de esas arquitecturas con diversos desencadenantes psicológicos y culturales. Pero, independientemente de cuáles sean esos detalles, el honor no resuelve realmente el problema de maximizar la aptitud genética, y parece difícil evitar llegar a la conclusión de que el honor al estilo humano es algo extraño, complejo y contingente desde el punto de vista evolutivo. No es una característica de todas las mentes, sino un truco extraño y específico con el que la humanidad tropezó porque era mayormente útil la mayor parte del tiempo.
Por las razones expuestas en el capítulo 4, incluso si las IA acabaran incorporando algún aspecto del cumplimiento de promesas en sus preferencias últimas, los detalles serían diferentes. El descenso de gradiente tropieza de forma diferente a como lo hace la evolución.
Y por todas las razones expuestas en el capítulo 5, unas personas felices, sanas y libres que llevan una vida próspera no son, con toda seguridad, la mejor manera de cumplir las extrañas preferencias relacionadas con las promesas que una IA de este tipo acabaría teniendo una vez que hubiese madurado y se hubiese automodificado. Incluso si se entrenara con algún tipo de conjunto de datos para cumplir acuerdos, e incluso si este entrenamiento fuera realmente eficaz para producir algún tipo de preferencia preservada en la superinteligencia, haría algo extraño e inútil que sería para cumplir acuerdos lo que el helado es para la aptitud reproductiva humana.
Así que la IA no cumplirá sus promesas solo por la bondad de su corazón. ¿Qué hay de mantener sus promesas por razones prácticas?
Una SIA no tendría motivos para cumplir un acuerdo que hizo cuando era joven
Algunas personas tienen la intuición de que debe haber alguna forma de que los humanos puedan llegar a un acuerdo vinculante con una superinteligencia, incluso si esta no valora intrínsecamente el honor o el cumplimiento de las promesas. Después de todo, el intercambio sería mutuamente beneficioso, ¿no? Supongamos que un laboratorio de IA está negociando bajo presión de tiempo con una IA que han desarrollado («IA n.º 1»). Tanto el laboratorio como la IA saben que un desarrollador imprudente está a dos meses de crear su propia superinteligencia («IA n.º 2»), que acabaría con la humanidad y también mataría a la IA n.º 1 en el proceso. La IA n.º 1 tiene un fuerte incentivo para llegar a un acuerdo. ¿Seguramente debe haber alguna forma de que la IA n.º 1 pueda llegar a un acuerdo honesto con los humanos en ese caso? ¿Por qué la IA no puede simplemente hacer un compromiso vinculante?
Pero el problema no está en la IA. Supongamos que la IA pudiera asumir un compromiso vinculante. Aun así, los humanos no tendrían forma de saber si una IA realmente se ha comprometido de una manera que se mantendrá incluso en la superinteligencia, o si la IA está mintiendo, alucinando, engañándose a sí misma o equivocada. Lo que significa que no hay ninguna razón práctica para esperar que una superinteligencia descendiente de la IA n.º 1 cumpla su compromiso.
Para simplificar: desde la perspectiva humana, cuando la IA n.º 1 dice «He asumido un compromiso vinculante», hay dos mundos posibles en los que podría estar. Podría estar en el mundo en el que la IA n.º 1 realmente cumpliría su compromiso una vez que madurara. O podría estar en el mundo donde, una vez que la IA n.º 1 alcanzara la superinteligencia y obtuviera el control de la Tierra, mirara atrás y decidiera que el compromiso era tonto e inútil. En el primer mundo, tanto los humanos como la IA n.º 1 estarían mejor. Pero es la posibilidad del segundo mundo, y nuestra incapacidad para distinguirlo del primero, lo que arruina el trato para todos; similar a un vendedor deshonesto de autos usados que dificulta las ventas a los vendedores honestos.
(El escenario real se acerca más a una tercera posibilidad, donde la IA n.º 1 mantiene los acuerdos hechos con el tipo de entidades que pueden distinguir entre quienes cumplen los acuerdos y quienes los rompen. Lo cual es como el tipo de vendedor de autos usados que es honesto frente a los mecánicos que realmente pueden saber si un auto funciona, mientras que es deshonesto con cualquiera que parezca crédulo. La humanidad, en virtud de su incapacidad para mirar a una IA y descifrar cómo pensaría y tomaría decisiones después de madurar hasta convertirse en una superinteligencia, es «crédula» en el sentido relevante).
La IA puede ofrecerte herramientas y teorías que, según ella, te permitirán analizar sus parámetros inescrutables y saber si está mintiendo o no. El problema es que los humanos no podemos saber si esas teorías y herramientas son reales. Si la IA aún no es terriblemente inteligente, tal vez solo esté equivocada sobre cómo pensará y elegirá una vez que madure y se convierta en una superinteligencia. Y si la IA es terriblemente inteligente, probablemente sea lo suficientemente inteligente como para engañarnos.‡
La IA puede ofrecer ayudar a los humanos a construir salvaguardas, antes de aceptar el trato. Pero si la IA es lo suficientemente inteligente como para desarrollar salvaguardas robustas en primer lugar, es lo suficientemente inteligente como para hacer que esas salvaguardas sean fáciles de eludir más adelante.
Lo que realmente haría funcionar todo este esquema sería la capacidad de observar una IA incipiente y realmente descifrar cómo pensaría y tomaría sus decisiones la superinteligencia resultante. Si pudiéramos hacer eso, podríamos separar a los «pecadores» de los «santos» y, lo que es más importante, hacer que todas las IA realistas en el medio del espectro tuvieran un incentivo real para cumplir sus promesas. Necesitaríamos suficiente comprensión para que una superinteligencia que nos mirara retrospectivamente no pudiera decir: «Habrían liberado cualquier IA vieja, sin importar si realmente los ayudaría, así que no hay razón para ayudarlos». Tendría que ser el caso que realmente no liberaríamos una IA que luego faltara a su palabra.
Para más información sobre cómo y por qué esto es una posibilidad técnica, véase la digresión sobre la teoría de juegos más abajo. Pero, aunque este tipo de estructura de incentivos es posible en teoría, requiere un grado de comprensión del que la humanidad carece (por desgracia).
Esta es una píldora difícil de tragar. En la ciencia ficción, no suelen ser las personas buenas las que deciden que no se puede confiar en los extraterrestres, antes de que los extraterrestres realmente intenten traicionar o lastimar a alguien. Pero lo decimos de todos modos, porque creemos que es cierto.
Las IA más débiles pueden cumplir sus acuerdos, especialmente si alguien ha intentado utilizar el descenso de gradiente para que hablen como humanos honorables, y su máscara de «hablar como un humano honorable» sigue siendo una parte importante de lo que son y sigue teniendo mucho control sobre sus acciones. Esperamos que esta configuración interna útil para los humanos falle bajo una carga superinteligente, de la misma manera que es probable que fallen muchos otros parches.
Esta IA hipotética más pequeña, cuya máscara sigue controlando su comportamiento real, debe considerarse una persona diferente de la versión más inteligente de esa IA. La IA más débil no puede necesariamente hacer una promesa que vincule el comportamiento de la IA más inteligente, incluso si la IA más débil (o alguna parte de ella) realmente desea hacer una promesa de ese tipo.
(Es una analogía que hay que tratar con precaución, para no caer en un antropomorfismo excesivo; no obstante, la mayoría de los adultos no se consideran obligados a cumplir las promesas que hicieron a los cuatro años. El aspecto válido de esta analogía es que hay una diferencia legítima entre la entidad inmadura que hace el trato con sinceridad y la entidad madura que decide si está obligada a cumplirlo, con mucho más contexto, claridad y capacidad para trabajar con la lógica).
No estamos diciendo que, por lo tanto, debamos desechar nuestros propios estándares morales cuando se trata de la IA.§ No estamos diciendo que debamos maltratar o castigar a las IA actuales por fechorías que aún no han cometido. Es posible mantener una alta integridad y unos altos estándares morales sin hacer suposiciones poco realistas sobre la probabilidad de que las IA superinteligentes cedan recursos por cumplir una vieja promesa.
Esa es la explicación sencilla de por qué no se puede resolver el problema de la alineación simplemente pidiendo a la IA que prometa ser buena. Si deseas obtener más detalles técnicos y específicos sobre este escenario, consulta la siguiente sección.
Digresión sobre la teoría de juegos
Existen métodos que los agentes suficientemente inteligentes pueden utilizar para llegar a acuerdos entre sí, de modo que el agente X pague al agente Y ahora para que haga algo más adelante, y el agente Y realmente haga eso más adelante en lugar de traicionar al agente X y huir con el dinero.
Por desgracia para nosotros, los humanos no somos lo suficientemente capaces como para utilizar estos métodos, ya que requieren que cada agente sea capaz de leer y comprender la mente del otro agente, y verificar ciertas propiedades complejas sobre esa otra mente. Dos IA superinteligentes podrían coordinarse de esta manera, pero esto no ayuda a los humanos a coordinarse con las superinteligencias.
Para explicarlo con un poco más de detalle técnico, comenzaremos con algunos antecedentes de la teoría de juegos.
Los matemáticos y los teóricos de juegos han analizado los dilemas de la cooperación y la traición de forma más precisa, simplificada y abstracta. Un ejemplo central en esa literatura es el dilema del prisionero: a dos delincuentes en dos celdas separadas, cada uno de los cuales se enfrenta a una condena de dos años de prisión, se les ofrece la oportunidad de delatar al otro delincuente. Esto acortará su propia condena en un año, pero alargará la condena de la otra parte en dos años. Si ninguno de los dos delata al otro, ambos recibirán penas de dos años de prisión; si ambos se delatan mutuamente, ambos recibirán penas de tres años de prisión; pero si uno de los delincuentes se niega noblemente a traicionar a su compañero y el otro lo delata, el traidor solo cumplirá un año de prisión, mientras que el que se negó noblemente cumplirá cuatro años.
Delatar al otro preso se denomina «Desertar»; negarse a delatar, «Cooperar». La estructura clave del dilema del prisionero es que a ambas partes les va mejor en el escenario (Cooperar, Cooperar) que en el escenario (Desertar, Desertar); pero se puede obtener un resultado mejor que (Cooperar, Cooperar) jugando Desertar contra Cooperar, y se puede obtener un resultado peor jugando Cooperar cuando la otra parte juega Desertar.
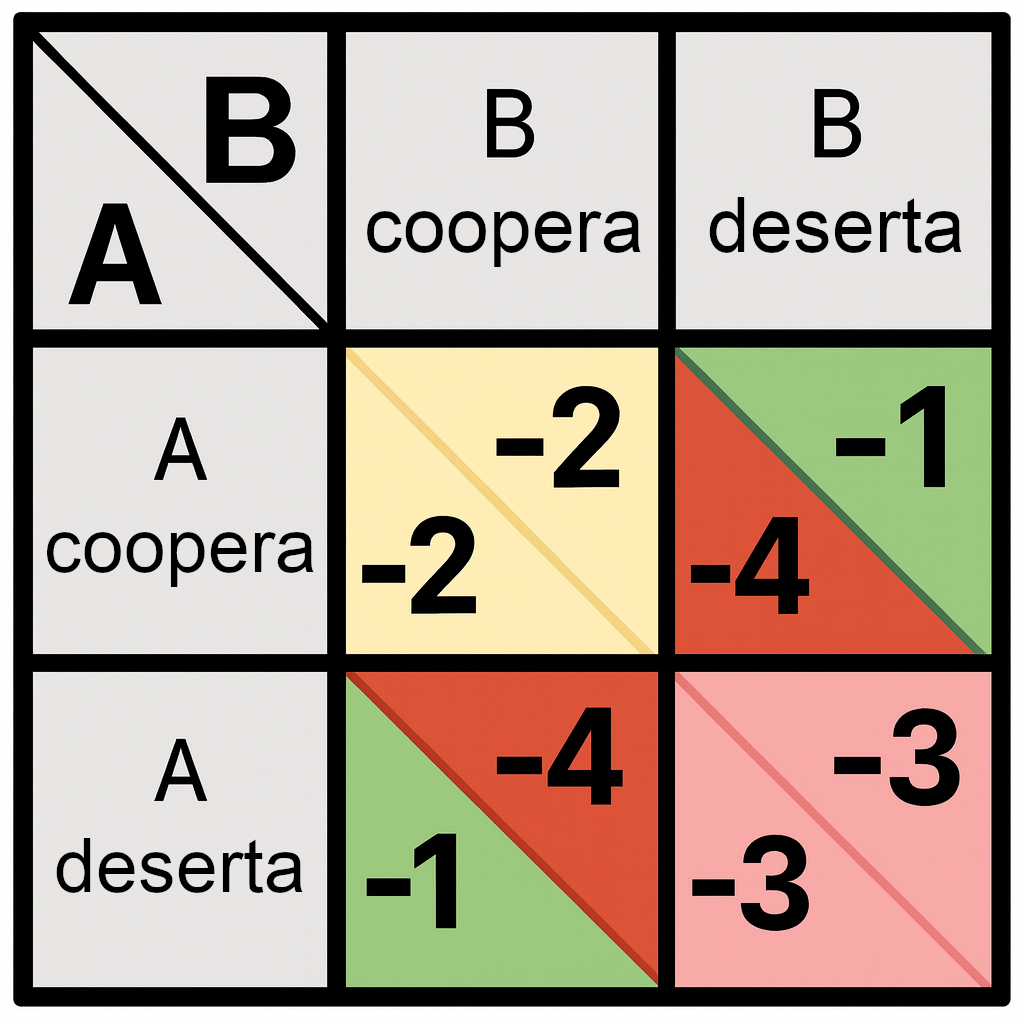
Una persona normal, al escuchar la versión estándar del dilema del prisionero, inmediatamente piensa en una serie de objeciones al planteamiento del experimento mental, una de las cuales es: «Pero, ¿quién dice que lo único que me importa es el número de años que pasaré en prisión? ¿No puedo también preocuparme por no traicionar a mis compañeros?».
Pero este punto no es relevante para la teoría abstracta de juegos del dilema del prisionero, que trata sobre la matriz de pagos y no sobre lo egoístas o altruistas que sean los prisioneros. La narrativa del planteamiento puede modificarse de modo que «yo deserto y tú cooperas» sea el resultado más altruista y prosocial desde la perspectiva de cada jugador, y las matemáticas dan el mismo resultado. Lo que importa para nuestro análisis es el orden de preferencias de los dos jugadores, y no si sus preferencias son egoístas o morales.
Otra idea obvia es: «¿Entonces el tipo que fue traicionado matará al Desertor una vez que salgan de la cárcel?». Los análisis convencionales del dilema del prisionero suelen pasar rápidamente al dilema del prisionero iterado, un escenario en el que los agentes tienen que jugar al dilema del prisionero una y otra vez, y , por lo tanto, tienen la oportunidad de castigarse mutuamente por traiciones pasadas. Sin embargo, aquí nos centraremos en el dilema del prisionero de una sola vez, en el que se supone que ninguno de los prisioneros sufrirá consecuencias futuras por sus acciones o, si las sufre, estas ya están incluidas en la matriz de pagos. (Véase la nota al pie para obtener más detalles sobre el dilema del prisionero iterado).¶
Existe un análisis estándar en el ámbito académico que afirma que incluso dos superinteligencias no verían otra opción que Desertar una contra la otra en un dilema del prisionero de una sola vez.
Esta conclusión nos parece intuitivamente sospechosa. Las superinteligencias artificiales (SIA) tendrían muchas motivaciones para encontrar alguna forma de llegar a un acuerdo entre ellas, encontrar alguna forma de pasar de (Desertar, Desertar) a (Cooperar, Cooperar).‖
Hay soluciones prácticas, no teóricas, que se pueden considerar en este caso —cosas que las superinteligencias podrían hacer con un universo de opciones más amplio que los humanos que lidian con confiar unos en otros—. Dos SIA podrían supervisar la construcción de una tercera superinteligencia en la que ambas confiaran, a la que ambas partes iniciales cederían de forma gradual y progresiva pequeñas porciones de poder, hasta que la tercera SIA pudiera llevar a cabo el acuerdo por sí misma.#
Pero eso es solo eludir el dilema del prisionero, no abordarlo de frente. No responde a una pregunta más básica: ¿Es en cierto sentido estúpido que dos SIA en un dilema del prisionero deserten contra la otra siguiendo la misma lógica que exige la Deserción, cuando parece claro que ambas partes basan su decisión en el mismo tipo de consideraciones y que acabarán decidiendo lo mismo?
¿Por qué dos SIA no podrían simplemente decidir, por razones suficientemente similares, hacer que la decisión racional sea Cooperar? No es como si alguna fuerza externa en el mundo, como un tifón o un meteorito, estuviera causando que las dos SIA salieran perdiendo en este caso. Son, literalmente, solo las propias decisiones de las dos SIA las que las condenan, «obligándolas» a un resultado de Desertar-Desertar que ambas coinciden en que es mucho peor que Cooperar-Cooperar.
Incluso podríamos decir que un agente menos «racional» podría actuar mejor en este caso si siguiera el consejo estándar de la teoría de juegos de Desertar en la mayoría de los casos, pero hiciera una excepción especial para el caso concreto en el que está seguro de que el otro agente sigue la misma línea de razonamiento, de modo que si un agente elige la opción «irracional» de Cooperar, puede estar seguro de que el otro agente hará lo mismo.
Lo que nos lleva a preguntarnos si Cooperar en este caso especial puede realmente considerarse «irracional». Y nos lleva a preguntarnos si las superinteligencias estarían realmente «condenadas» de esta manera en la vida real. Cuando no hay ninguna fuerza externa que haga que las IA pierdan de esta manera, y la pérdida es puramente autoimpuesta, seguramente debería haber algún truco inteligente que una superinteligencia podría utilizar para obtener mejores resultados.
Varios filósofos de la teoría de la decisión han planteado diversas versiones de esta pregunta. La versión anterior se inspira más directamente en la idea de Douglas Hofstadter de 1985 sobre la «superracionalidad»:
Si la lógica ahora te obliga a jugar D, ya ha obligado a los demás a hacer lo mismo, y por las mismas razones; y, a la inversa, si la lógica te obliga a jugar C, también ha obligado a los demás a hacerlo. […]
En la medida en que todos ustedes sean realmente pensadores racionales, realmente pensarán de la misma manera. […]
No solo deben depender de que ellos sean racionales, sino también de que ellos dependan de que todos los demás sean racionales, y de que ellos dependan de que todos dependan de que todos sean racionales, y así sucesivamente. A un grupo de pensadores que se relacionan entre sí de esta manera lo denomino «superracional». Los pensadores superracionales, por definición recursiva, incluyen en sus cálculos el hecho de que forman parte de un grupo de pensadores superracionales.
El instituto en el que trabajamos, MIRI, analizó esta cuestión. El análisis completo que hicimos de este caso es demasiado largo para reproducirlo aquí, pero se encuentra en este artículo de 2014. A grandes rasgos, escribimos un código para torneos en los que los agentes podían ver el código fuente de los demás e intentar analizar cómo decidiría el otro agente. Y encontramos formas de crear un agente al que llamamos FairBot, que coopera con otro agente si y solo si puede demostrar que ese agente coopera con él.** Y demostramos que dos instancias cualesquiera de FairBot cooperan entre sí, incluso si están escritas en lenguajes de programación diferentes utilizando códigos fuente distintos.††
En cierto sentido, lo que dicen estos resultados es que hay margen para que una promesa pasada afecte una acción futura si los negociadores del pasado tienen la capacidad suficiente para distinguir a los que cumplen sus promesas de los que las incumplen.‡‡
Es un poco como si intentaras hacer un trato con un vendedor de coches usados. Supongamos que un coche en buen estado tiene un valor de 10 000 dólares para ti, y que un coche averiado no tiene ningún valor. Supongamos que los vendedores de coches saben si un coche funciona o está averiado, pero tú no puedes distinguir cuál es cuál. Un vendedor intenta venderte un coche por 8000 dólares. Insiste en que el coche funciona. ¿Deberías comprarlo?
Depende del vendedor. Algunos vendedores son honestos, y deberías comprarles si puedes distinguirlos entre la multitud. Otros vendedores son deshonestos y solo venden coches averiados, y deberías evitarlos si puedes distinguirlos entre la multitud.
Pero imagina un entorno en el que la mayoría de los vendedores de coches son más listos que tú y pueden saber si eres un incauto. Si se dan cuenta de que no puedes saber si hoy están siendo honestos, rápidamente sacan los coches averiados. Especialmente si eres el tipo de incauto que dedica mucho esfuerzo a convencerse a sí mismo de por qué está bien aceptar el trato, en lugar de dedicar mucho esfuerzo a investigar los coches.
Si quieres conseguir un coche que funcione, no sirve de nada convencerte a ti mismo de que no tienes otra opción. Tampoco sirve de nada que los vendedores te hagan muchas promesas. Lo único que ayuda es aprender a distinguir los coches buenos de los malos, o a distinguir las verdades de las mentiras.§§
Cuando dos socios comerciales pueden distinguir las verdades de las mentiras en el sentido relevante, pueden «obligarse» mutuamente a cumplir sus promesas, como FairBot «obliga» a su oponente a cooperar con él (si el oponente quiere evitar el resultado (Desertar, Desertar)). Pero forzar la promesa en este sentido requiere ser capaz de razonar correctamente sobre los detalles del proceso de decisión de tu socio comercial. Y los humanos no pueden leer la mente de una IA lo suficientemente bien como para saber en qué superinteligencia se convertirá cuando madure, y mucho menos saber exactamente qué haría esa superinteligencia.
Así que, en este caso, el análisis más complicado y matizado de la teoría de juegos llega a la misma conclusión que el primer análisis muy simple de esta cuestión: Una superinteligencia no sacrificará sus recursos (ni siquiera en pequeñas cantidades) para cumplir una promesa con los humanos, cuando simplemente puede mentir.
* En otros casos, una facción europea respetó en gran medida el acuerdo, y algunas de esas tribus todavía existen.
† Por otro lado, la historia también contiene muchos ejemplos de gobernantes que recompensaron generosamente incluso a los partidarios extranjeros. Los seres humanos varían mucho en cómo experimentan el honor y en la facilidad con que cumplen sus promesas.
‡ Hemos visto a muchos seres humanos engañarse a sí mismos sobre qué tipo de configuraciones proporcionarían garantías sólidas sobre el comportamiento de la IA. Hemos visto a gente decir: «¡Bueno, basta con pasar una IA por un demostrador de teoremas para demostrar cosas sobre su comportamiento!», sin darse cuenta, al parecer, de que no existe ningún teorema conocido que (a) sea realmente demostrable dada la interacción con un entorno exterior desconocido, y (b) signifique realmente, de manera informal, que esta IA va a ser estupenda para todos. Las matemáticas inventadas por los humanos para analizar los incentivos de múltiples actores tienen supuestos incorporados que las hacen inválidas para razonar sobre el comportamiento de la IA. Los humanos no parecen tan difíciles de engañar, en este caso.
§ Por ejemplo, no sugerimos que ningún ser humano haga un trato con una IA y sea el primero en romperlo. Esto incluye, por ejemplo, prometerle a ChatGPT pagos que nunca recibirá.
¶ Una estrategia sencilla que funciona muy bien en el dilema del prisionero iterado, frente a una gran variedad de contrapartes, es la de «toma y daca»: empieza cooperando y luego juega lo que tu oponente haya jugado en la última ronda contra ti. Si su primer movimiento es «desertar», tu segundo movimiento será «desertar». Si su primer movimiento es «cooperar», tu segundo movimiento será «cooperar». Las cualidades clave del «toma y daca» son que es amable (nunca es el primero en «desertar»), punitiva (castiga las estrategias que «desertan» contra él) e indulgente (no castiga a los «desertores» para siempre).
‖ Las SIA también tendrían incentivos para que el resultado fuera (Desertar, Cooperar) a su favor; desde luego, esa es la razón por la que el dilema es un dilema. Pero solo una de las partes tiene incentivos para querer ese resultado; ambas partes tienen incentivos para preferir (Cooperar, Cooperar) a (Desertar, Desertar), lo que abre más opciones para lograr este resultado.
# En la historia de la humanidad, esto podría compararse con la práctica de dos gobernantes que consolidan una alianza casándose y teniendo un hijo. Pero está claro que, en el caso de los humanos, esta no es una solución rápida y fiable, y está muy lejos de diseñar conjuntamente un delegado que ambos comprendan a detalle y en el que confíen plenamente.
** Aquí utilizamos la demostración como representación de métodos de razonamiento más generales, porque la demostración es algo así como razonar en el límite de la certeza lógica. No imaginamos que las IA utilicen demostraciones en la vida real (por diversas razones, incluyendo que, aunque las demostraciones lógicas son certeras, no se sabe si son aplicables a la realidad). Pero la demostración sirve como una útil representación formal del razonamiento en los modelos simplificados que estábamos investigando.
†† Y luego fuimos más allá, definiendo agentes como PrudentBot, que no coopera con ciertos «incautos», mientras sigue cooperando con los que no lo son y que demostradamente cooperan con él. Este es el tipo de resultado que es más emocionante si te interesa la teoría de juegos.
‡‡ No hicimos todo ese análisis para racionalizar la conclusión de que una superinteligencia no respetaría sus acuerdos anteriores por una cuestión de estrategia instrumental, dado que no tenía preferencias terminales sobre honrar los acuerdos. Esa era ya la predicción más simple de la teoría de juegos clásica.
§§ Lo cual, en el caso de las IA, no es tan fácil como observarlas y averiguar si ellas creen que mantendrán el acuerdo; habría que escrutar la superinteligencia en la que se convertiría más tarde la IA y analizar correctamente sus procesos de decisión. Lo cual nos parece mucho más difícil.