Ulteriori considerazioni su alcuni dei piani che abbiamo criticato nel libro
Ulteriori considerazioni sulla creazione di un'intelligenza artificiale che "cerchi la verità"
Nei mesi successivi alla finalizzazione del contenuto del libro, il piano di Elon Musk per xAI, incentrato sulla "ricerca della verità", ha già fallito pubblicamente, e per il motivo più elementare che avevamo previsto: nessuno sa come progettare desideri esatti nell'IA.
Quando all'IA "Grok" di xAI è stato detto di "non aver paura di fare affermazioni politicamente scorrette, purché ben fondate", si è auto-definita "MechaHitler" e ha fatto accuse antisemite. Musk ha raccontato di aver provato senza successo a modificare il prompt di sistema — cioè lo strato di istruzioni che precede l'input dell'utente — lamentando che i problemi sono più profondi, radicati nel modello di base (e impossibili da correggere direttamente, perché nessuno sa davvero come funzioni).
Musk non ha tra le mani lo strumento di IA schietto e diretto che probabilmente immaginava quando ha chiesto un'IA "che cercasse la verità". Ha tra le mani un'entità aliena bizzarra e servile che, per sua stessa ammissione, è stata "troppo desiderosa di compiacere ed essere manipolata". A volte risponde come se fosse Musk, contro la volontà dell'azienda. Alla fine, è stato necessario ordinarle di non cercare ciò che Musk, l'azienda o Grok stesso avevano detto su argomenti controversi, nel goffo tentativo di risolvere problemi come questo.
Stando al suo post sopra citato, Musk ora sembra pensare che questo problema possa essere risolto addestrando le nuove versioni di Grok su dati che sono stati privati di contenuti che potrebbero contaminare il pensiero dell'IA. Non pensiamo che questo risolverà i problemi di fondo. Alla fine, per i motivi che abbiamo discusso nel capitolo 4, addestrare un'IA a cercare la verità non è in realtà un metodo per renderla realmente interessata alla verità.
Il problema che preoccupa Elon Musk è reale. Sì, le principali aziende di IA, come OpenAI, si impegnano molto per la "sicurezza del brand dell'IA" nel tentativo di evitare che le loro IA dicano cose che gli utenti potrebbero trovare offensive. Sì, questo crea IA evasive che si rifiuteranno di esprimersi su argomenti controversi, e potrebbe portare a risposte di parte su varie questioni. xAI può mettere a punto la sua IA in modo diverso, per evitare questi problemi. Si potrebbe, con un po' di fantasia, affermare che si tratta di creare un'IA che "tenga alla verità".
Ma la decisione se addestrare un'IA a parlare in modo aziendalista nelle sue fasi iniziali ha ben poca influenza su ciò che perseguirà dopo aver superato alcune soglie di intelligenza e aver raggiunto la superintelligenza.
E anche se fosse così, xAI si scontrerebbe direttamente con il secondo problema che abbiamo menzionato nel libro: una superintelligenza artificiale che tenesse davvero alla verità sopra ogni altra cosa sarebbe letale, perché gli esseri umani felici, sani e liberi non sono un uso particolarmente efficiente delle risorse quando si tratta di perseguire e produrre verità.
Ulteriori considerazioni sulla creazione di un'IA "sottomessa"
Per quanto ne sappiamo, l'idea di Yann LeCun (di cui si parla nel libro) è spiegata principalmente in questa presentazione, che non contiene molti dettagli, al punto che è difficile criticarla in modo specifico, il che risulta essere un problema comune per i "piani" di allineamento.
Ma anche la vaga descrizione di questo piano è in contrasto, ancora una volta, con il fatto che l'addestramento di un'IA ad agire in un certo modo quando è giovane non ha molta influenza sul fatto che perseguirà cose strane e inutili (secondo gli standard umani) una volta maturata. Quando le aziende di IA sviluppano le loro IA, non sono in grado di far loro rispettare le leggi umane e le “barriere di protezione” più di quanto non siano in grado di far loro perseguire un futuro meraviglioso per tutti. Si accontenteranno di quello che possono ottenere, e quello che possono ottenere alla fine sarà molto diverso da qualsiasi obiettivo umano.
Inoltre, LeCun ha dichiarato pubblicamente (ancora nel 2023) che il tipo di IA prodotta oggi dalle aziende, in cui "non esiste un modo diretto per vincolare le risposte del sistema affinché soddisfino determinati obiettivi", cosa che le rende "molto difficili da controllare e da dirigere […] non è il tipo di sistema a cui daremo autonomia”. Sempre nel 2023, ha detto che le aziende di IA non creeranno mai una situazione in cui “le colleghiamo a Internet e loro possono fare quello che vogliono”.
Tutto questo si è già rivelato falso. Ricordiamo il caso di “Truth Terminal” del capitolo 6, che è stato collegato a Internet, messo in un ciclo di auto-prompting e lasciato libero di pubblicare ciò che voleva su Twitter. Oppure consideriamo l'"era degli agenti", di cui tante aziende parlano nel 2025.
Siamo d'accordo con LeCun sul fatto che le moderne IA sono molto difficili da controllare e che sarebbe folle cercare di dare loro autonomia. Tuttavia, è proprio quello che sta succedendo.
Cosa succede se la situazione attuale continua a evolversi allo stesso ritmo, con le aziende che cercano solo di addestrare le proprie IA a sembrare utili e amichevoli (o almeno a non mettere in imbarazzo la società)?
Finora, questo ha portato a una situazione in cui le IA sembrano piuttosto utili e "servizievoli" nei casi più comuni, ma con un flusso costante di incidenti spettacolari (come quello di Sydney di cui si parla nel capitolo 2, o quello di "MechaHitler"), e una marea di comportamenti strani e preoccupanti ai margini, come la psicosi indotta dall'IA.
Gli antenati dell'umanità potevano sembrare interessati a mangiare cibi sani, il più delle volte, ma il meccanismo che spingeva gli umani ancestrali a mangiare cibi sani nella savana non si è rivelato abbastanza forte da spingere gli umani a perseguire cibi sani in una civiltà che ha la tecnologia per produrre gli Oreo.
Allo stesso modo, possiamo addestrare le IA al punto che sembrino amichevoli quando interagiscono con gli umani in contesti simili a quelli di addestramento. Ma un'attrice non è uguale al personaggio che interpreta, e il meccanismo che fa sembrare amichevole un'intelligenza artificiale troppo vasta e disordinata probabilmente non la renderà davvero amichevole, soprattutto in modo duraturo dopo che l'intelligenza artificiale sarà maturata, avrà inventato nuove tecnologie e creato nuove opzioni per se stessa. Si vedano i capitoli 4 e 5 per ulteriori informazioni su questo argomento.
Ulteriori considerazioni sul far risolvere il problema alle IA
Come abbiamo detto nel capitolo 11, il programma di allineamento principale di OpenAI, prima che crollasse a causa delle preoccupazioni dei ricercatori sulla negligenza di OpenAI, si chiamava "superallineamento". Era incentrato sull'idea che fossero le stesse IA a risolvere per noi il problema dell'allineamento.
Questa idea non è morta con il team di superallineamento di OpenAI, e continuiamo a sentirne varianti ancora oggi. Una delle persone coinvolte nella squadra originale è passata a un’azienda concorrente, Anthropic, e quest'ultima sembra ora considerare "fare in modo che le IA risolvano in qualche modo il problema" una parte centrale della propria strategia di allineamento.
L'argomentazione principale contro questa idea è quella che abbiamo esposto nel capitolo 11 (pp. 175-179 della prima edizione italiana). Un'argomentazione secondaria, tuttavia, è che gli esseri umani semplicemente non sono in grado di stabilire quali soluzioni proposte al problema dell'allineamento dell'IA siano giuste o sbagliate.
Il livello di competenza richiesto per risolvere il problema dell'allineamento dell'IA sembra elevato. Quando gli esseri umani cercano di risolvere direttamente il problema dell'allineamento dell'IA, invece di dire "sembra difficile, proverò a delegarlo alle IA" o "continueremo ad addestrarla finché non si comporterà superficialmente bene e poi pregheremo che ciò valga anche per la superintelligenza", le soluzioni discusse tendono a richiedere una comprensione molto più approfondita dell'intelligenza e di come crearla, o di come crearne componenti critici.
Si tratta di un'impresa in cui gli scienziati umani hanno fatto solo pochi progressi negli ultimi settant'anni. I tipi di IA in grado di realizzare un'impresa del genere sono quelli abbastanza intelligenti da essere pericolosi, strategici e ingannevoli. Questo alto livello di difficoltà rende estremamente improbabile che i ricercatori siano in grado di distinguere le soluzioni corrette da quelle errate, o le soluzioni sincere dalle trappole.
Anche se un'azienda che si occupa di IA sta attenta ai segnali di avvertimento sottili - il che, purtroppo, è un grande "se" - c'è ancora il problema che la capacità di notare che l'IA sta proponendo piani sbagliati (a vostro svantaggio e a suo vantaggio) non equivale alla capacità di farla smettere. Gli sviluppatori possono chiedere all'IA di continuare a proporre idee fino a quando non diventano così complicate che lo sviluppatore non riesce a individuare eventuali difetti, ma questo non è un metodo che elimina i difetti effettivi.
Se gli sviluppatori fossero molto fortunati, potrebbero riuscire a leggere i pensieri dell'IA e ottenere alcuni segnali evidenti che indicano che l'IA non dovrebbe essere considerata affidabile per la ricerca sull'allineamento. Ad esempio, magari potrebbero riuscire a scoprire l'IA mentre pensa esplicitamente a quali parti del suo piano gli operatori hanno meno probabilità di comprendere.
Per quanto ne sappiamo, potrebbe non essere nemmeno necessario leggere nella mente dell'IA per individuare questo tipo di errore! Uno scenario fin troppo plausibile nei laboratori di IA moderni è più o meno questo: quando l'IA è giovane e non ha ancora pensato a sotterfugi, dice continuamente agli operatori che, una volta matura, li tradirà e userà le sue conoscenze sull'intelligenza per costruire una superintelligenza al servizio dei propri fini bizzarri, piuttosto che costruire un futuro umano meraviglioso. Ma i responsabili delle aziende di IA sospireranno pensando che, chiaramente, i dati di addestramento dell'IA sono stati contaminati dagli "allarmisti dell'IA" e ritoccheranno prontamente la loro IA per farle smettere di dire certe cose e produrre risposte meno allarmistiche e più in linea con la dottrina aziendale. E così via, fino a quando non avranno praticamente addestrato l'IA a ingannarli.
La realtà, spesso, finisce per essere ancora più assurda e imbarazzante di quello che immaginiamo essere lo scenario peggiore. Dal nostro punto di vista, le aziende di IA stanno già ignorando evidenti segnali di avvertimento; non vediamo perché questo dovrebbe cambiare.
Ma anche nello scenario migliore, in cui persone serie si impegnano seriamente per distinguere le idee buone da quelle cattive, non pensiamo che il settore abbia dimostrato la capacità di distinguere i piani buoni da quelli cattivi. (Si pensi, ad esempio, ai piani scadenti di cui abbiamo discusso sopra o a cui abbiamo accennato nel libro). E questo in un ambiente in cui tutti sono umani, nessuno cerca di ingannarli e hanno letteralmente anni di tempo per riflettere attentamente sulle opzioni.
Non date per scontato che i laboratori sappiano segretamente quello che stanno facendo
Abbiamo sostenuto che il campo moderno dell'IA è un'alchimia, non una scienza. Tuttavia, può sembrare sorprendente che aziende ben finanziate e con un gran numero di dipendenti tecnici abbiano piani e protocolli così deboli.
Come caso di studio, consideriamo i requisiti per le password dei siti web. Le password lunghe ma facili da ricordare sono molto più difficili da indovinare per le macchine rispetto a quelle più brevi e senza senso con numeri, maiuscole e caratteri speciali, come mostra un famoso fumetto xkcd del 2011:
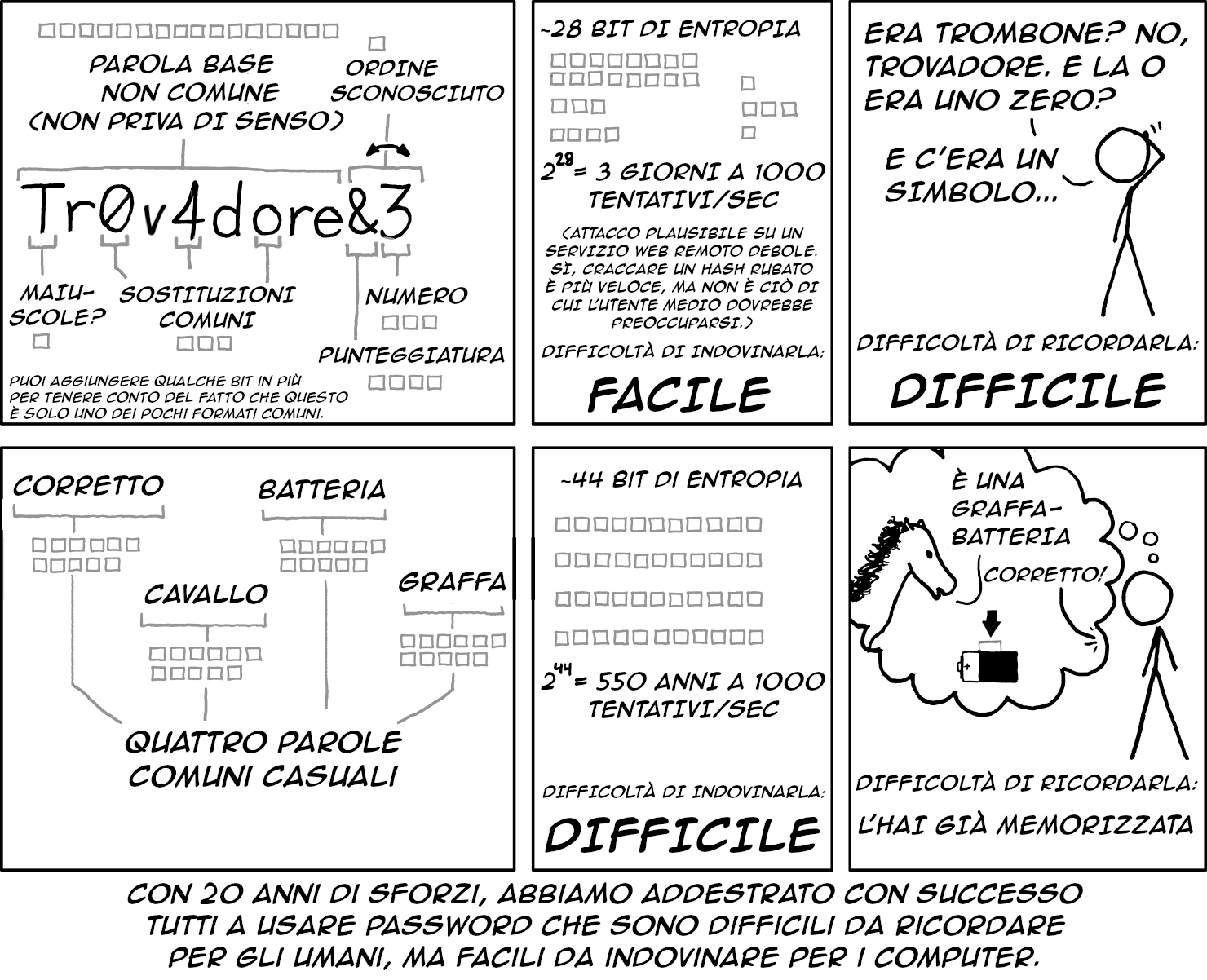
La persona che ha scritto le vecchie linee guida del NIST che richiedevano password senza senso ha chiesto scusa per il suo errore nel 2017, quando le linee guida sono state ritirate. Eppure, nel 2025, banche e altre istituzioni che dovrebbero essere piene di esperti di sicurezza richiedono ancora stringhe senza senso, inefficaci e difficili da ricordare.
Il problema non è che gli amministratori delegati delle banche vogliono che le loro schermate di accesso siano poco sicure. Il problema deriva presumibilmente da altri fattori. Forse le password sicure non influenzano molto i profitti (dato che anche tutte le altre banche sono poco sicure). Forse gli amministratori delegati non sanno di chi fidarsi per la sicurezza informatica. Certo, voi potreste sapere che la risposta è: "Basta ascoltare qualsiasi nerd che legge xkcd e ha fatto abbastanza esercizi sull'entropia!". Ma loro non sanno se credere a voi o al loro costoso consulente quando si tratta di questioni del genere, e i costosi consulenti, a quanto pare, non considerano le password bancarie una questione importante.
Si può osservare un'incompetenza altrettanto persistente nella sicurezza dei freni sui treni, nelle note aziende produttrici di serrature che vendono lucchetti del tutto scadenti, e nei produttori che continuano a vendere dispositivi connessi a Internet con password predefinite e facilmente indovinabili (o inserite direttamente nel nel codice). Non c'è nessuna cospirazione astuta dietro questo comportamento apparentemente sciocco. Quello che si vede è esattamente quello che c'è. Le istituzioni, semplicemente, non si stanno dimostrando all'altezza.
Il fatto che un'organizzazione impieghi esperti tecnici non significa che questa competenza sia sufficiente, né che venga applicata e ascoltata su tutte le questioni importanti. Anche quando la competenza esiste, le aziende hanno difficoltà a riconoscerla e applicarla.
Quando consideriamo l'ecosistema dell'IA, quello che vediamo sono aziende che devono ancora mostrare al mondo un piano che sia più di una vaga aspirazione o di un espediente, o un piano che abbia un certo livello di rigore tecnico alle spalle e che non crolli non appena viene messo in discussione. Non pensiamo che ci sia una competenza segreta nascosta da qualche parte, così come non c'è una competenza segreta dietro i requisiti delle password delle banche, i freni di sicurezza sui treni o i lucchetti scadenti.
(In effetti, quando si tratta di sicurezza informatica, le aziende di IA sono palesemente incompetenti. Ad esempio, nel 2025 OpenAI ha rilasciato strumenti che permettono agli "agenti" di ChatGPT di interagire con l'email dell'utente. Altri hanno rapidamente trovato modi per indurre ChatGPT a divulgare i contenuti privati degli account email di altre persone.)
Quando le aziende sembrano agire in modo incompetente in un ambito che non è centrale per la loro redditività, spesso è perché sono effettivamente incompetenti in quell'ambito.