Le IA non manterranno le loro promesse
Considerate una giovane IA con il potenziale di diventare una superintelligenza. Supponete che sia completamente indifferente alle preferenze degli umani, ma che sia ancora abbastanza giovane da poter essere spenta dall'umanità.
L'umanità potrebbe fare un accordo con l'IA?
Potremmo accordarci di lasciare che l'IA cresca fino a diventare una superintelligenza, se in cambio l'IA accetta di dedicare una frazione significativa delle risorse dell'universo a costruire un futuro che l'umanità considererebbe meraviglioso?
Gli esseri umani potrebbero fare accordi con le IA, ma non dovrebbero, perché le IA non li rispetterebbero.
Il motivo è duplice:
Probabilmente l'IA non darà importanza al fatto di mantenere le promesse di per sé. Le IA non avranno un senso dell'"onore" come quello umano, così come è improbabile che abbiano un senso della curiosità simile a quello umano. Come regola generale, è probabile che le IA funzionino davvero in modo molto diverso dagli esseri umani.
L'IA non avrà nemmeno un motivo pratico per mantenere la parola data. Una volta diventata una superintelligenza, non ci sarà modo di punirla per aver infranto la parola data, e non avrà alcun motivo per dedicare una parte consistente dell'universo a noi.
Spiegheremo questi due punti più in dettaglio qui di seguito, iniziando dalla questione dell'"onore".
È improbabile che le IA siano oneste
Nella nostra chiacchierata sulla curiosità, abbiamo detto che la curiosità è un'emozione che fa cose utili per noi, ma lo fa in un modo molto specifico, e che non è l'unico modo per fare quel tipo di cose.
Ci si può aspettare che le IA facciano le parti utili del lavoro che la curiosità fa per noi. Se è utile sforzarsi periodicamente di imparare cose nuove, allora le IA sufficientemente potenti si sforzeranno periodicamente di imparare cose nuove. Se l'IA non è così fin dall'inizio, allora dovremmo aspettarci che si renda così a un certo punto del suo percorso verso la superintelligenza.
Ma questo non equivale ad aspettarsi che le IA portino con sé tutto il bagaglio extra che caratterizza l'emozione umana della curiosità. Le IA potrebbero finire per avere un numero qualsiasi di strani impulsi fondamentali che (direttamente o indirettamente) le spingono a sforzarsi di imparare cose nuove, senza per questo assomigliare alla curiosità umana, oppure potrebbero adottare "sforzarsi di imparare cose nuove a volte" come strategia deliberata. Ma aspettarsi che apprezzino i gialli allo stesso modo in cui li apprezziamo noi, a causa di un impulso di curiosità proprio come il nostro, è puro antropomorfismo.
L'"onore" ci sembra simile. Gli umani hanno emozioni che li portano (almeno a volte) a mantenere le promesse. Nella misura in cui queste emozioni svolgono un compito utile negli esseri umani — compito che sarebbe utile anche per una mente molto aliena con obiettivi molto diversi — dovremmo aspettarci che anche le IA sufficientemente potenti svolgano in qualche modo quel compito. Ma si scopre che è possibile svolgere interamente il compito rilevante per un'IA senza avere nulla di simile a un senso dell'onore di tipo umano, proprio come è possibile svolgere tutto il compito rilevante per un'IA di indagare fenomeni sorprendenti senza avere esattamente un senso di curiosità di tipo umano.
L'onore in stile umano è una strana creatura, sotto molti aspetti. Perché mai una specie dovrebbe sviluppare emozioni legate al rispetto degli accordi anche dopo che l'altra parte ha fatto la sua parte e non può più offrirvi alcun vantaggio? Certo, gli esseri umani a volte imbrogliano e vengono meno ai loro accordi; ma la domanda è: perché non imbrogliano sempre, almeno quando pensano di poterla fare franca?
La spiegazione standard è: mantenere le promesse è utile con le persone con cui faremo affari ripetutamente. Si vuole avere la reputazione di chi mantiene le promesse, così gli altri vorranno lavorare con noi e fare accordi. Ma i benefici di una buona reputazione sono lontani nel futuro. La selezione naturale ha difficoltà a trovare i geni che inducono un essere umano a mantenere gli accordi solo nei casi in cui la nostra reputazione a lungo termine è una considerazione importante. Era più facile far evolvere semplicemente un istintivo disgusto per la menzogna e l'inganno.
Questo, quindi, sembra un caso classico in cui l'emozione e l'istinto sono plasmati da ciò che l'evoluzione riusciva più facilmente a inserire negli esseri umani. Tutti gli strani casi particolari in cui gli umani a volte mantengono una promessa anche quando in realtà non conviene sono principalmente prove di quali tipi di emozioni fossero più utili nel nostro ambiente tribale ancestrale pur essendo facili da codificare nei genomi per l'evoluzione, piuttosto che prove di qualche passo cognitivo universalmente utile. Siamo piuttosto scettici sull'idea che la discesa del gradiente si imbatterà per caso nella stessa identica scorciatoia che usano gli esseri umani.
Anche se l'emozione umana dell'onore finisse in qualche modo nell'IA, rimarrebbe il problema che gli esseri umani non sono perfettamente e affidabilmente onorevoli. La cooperazione umana si basa sulla sovrapposizione di molti valori umani diversi, piuttosto che affidarsi puramente alla propensione a mantenere ogni promessa.
Mentre la lista degli universali umani di Donald Brown (aspetti della cultura che si osservano in tutte, o quasi tutte, le culture) include la nozione di "promesse", il mantenimento degli accordi fatti con estranei, stranieri, non membri della tribù, non è universale in tutte le culture e tribù conosciute. L'importanza dell'onore varia a seconda della cultura.
E la storia mostra che le nozioni umane di onore spesso non reggono di fronte a grandi disparità di potere. Alcuni nativi americani tentarono di stringere accordi con gli europei che stavano colonizzando il loro continente. Gli europei, come è noto, violarono alcuni di questi accordi e mandarono le tribù a percorrere insieme lunghe strade lontano dalle terre cedute dai trattati, che gli europei avevano deciso di volere comunque, una volta che quelle tribù non erano più in grado di opporsi.* Allo stesso modo: la storia è piena di casi di persone che salirono al potere e prontamente tradirono i loro sostenitori una volta che non ne avevano più bisogno.†
Da una prospettiva evolutiva, l'onore umano è particolarmente strano nella misura in cui gli esseri umani occasionalmente scelgono la morte piuttosto che il disonore. Le intuizioni del tipo "morte piuttosto che disonore" sono presumibilmente legate alle specificità di quali tipi di architetture emotive erano facili da incontrare per l'evoluzione, e alle interazioni di quelle architetture con vari inneschi psicologici e culturali. Ma qualunque aspetto abbiano quelle specificità, l'onore non sta effettivamente risolvendo il problema della massimizzazione dell'idoneità genetica, e sembra difficile evitare la conclusione che l'onore in stile umano sia una cosa strana, complessa ed evolutivamente contingente. Non è una caratteristica di tutte le menti, è uno specifico e strano trucco in cui l'umanità è inciampata perché era per lo più utile la maggior parte del tempo.
Per le ragioni discusse nel Capitolo 4, anche se le IA finissero per avere qualche aspetto del mantenimento delle promesse incorporato nelle loro preferenze ultime, le specificità sarebbero diverse. La discesa del gradiente inciampa diversamente da come fa l'evoluzione.
E per tutte le ragioni discusse nel Capitolo 5, persone felici, sane e libere che conducono vite fiorenti non sono quasi sicuramente il modo migliore per soddisfare qualunque strana preferenza legata alle promesse che tale IA finirebbe per avere quando avesse finito di maturare e auto-modificarsi. Anche se fosse addestrata su una sorta di set di dati "Mantieni le Promesse", e anche se questo addestramento fosse effettivamente efficace nel produrre qualche tipo di preferenza preservata nella superintelligenza, farà qualche cosa strana e inutile che sta al Mantenere le promesse come il gelato sta al'idoneità riproduttiva umana.
Quindi l'IA non manterrà le sue promesse puramente per bontà d'animo. E che dire del mantenere le promesse per ragioni pratiche?
Una SIA non avrebbe motivo di mantenere un accordo fatto quando era giovane
Alcuni hanno l'intuizione che debba esserci qualche modo per gli esseri umani di stringere un accordo vincolante con una superintelligenza, anche se questa non dà intrinsecamente valore all'onore o al mantenere le promesse. Dopotutto, lo scambio sarebbe vantaggioso per entrambi, giusto? Supponiamo che un laboratorio di IA stia negoziando con un'IA che ha sviluppato ("IA n. 1") sotto pressione temporale. Sia il laboratorio che l'IA sanno che uno sviluppatore spericolato è a due mesi dal creare la propria superintelligenza ("IA n. 2"), che spazzerebbe via l'umanità e nel farlo ucciderebbe anche l'IA n. 1. L'IA n. 1 ha un forte incentivo a stringere un accordo. In quel caso, non deve esserci qualche modo per l'IA n. 1 di stringere un accordo onesto con gli umani? Perché l'IA non può semplicemente prendere un impegno vincolante?
Ma il problema non sta nell'IA. Supponiamo che l'IA possa prendere un impegno vincolante. Anche in questo caso, gli umani non avrebbero modo di sapere se l'IA si sia effettivamente impegnata in un modo che rimarrà valido anche una volta diventata superintelligente, o se invece l'IA stia mentendo, allucinando, illudendosi, o sbagliando. Il che significa che non c'è alcuna ragione pratica per aspettarsi che una superintelligenza derivata dall'IA n. 1 mantenga il suo impegno.
Per semplificare eccessivamente: dal punto di vista umano, quando l'IA n. 1 dice "Ho preso un impegno vincolante", ci sono due possibili mondi in cui potrebbero andare le cose. Si potrebbe essere nel mondo in cui l'IA n. 1 effettivamente mantiene il suo impegno una volta maturata. Oppure si potrebbe essere nel mondo in cui, una volta che l'IA n. 1 ha raggiunto la superintelligenza e ottenuto il controllo sulla Terra, guarda indietro e decide che l'impegno era sciocco e inutile. Nel primo mondo, sia gli umani che l'IA n. 1 starebbero meglio. Ma è la possibilità del secondo mondo, e la nostra incapacità di distinguerlo dal primo, che rovina l'accordo per tutti; è un caso simile a un venditore di auto usate disonesto che rende più difficile per i venditori onesti fare affari.
(Lo scenario reale è più vicino a una terza possibilità, in cui l'IA n. 1 mantiene gli accordi fatti con il tipo di entità che possono distinguere tra chi mantiene gli accordi e chi li infrange. È come il tipo di venditore di auto usate che è onesto con i meccanici che sono in grado di capire se un'auto funziona davvero, mentre è disonesto con chiunque gli sembri un credulone. L'umanità, a causa della sua incapacità di considerare un'IA e capire come penserebbe e prenderebbe decisioni dopo essere maturata in una superintelligenza, è "credulona" nel senso rilevante.)
L'IA può offrirvi strumenti e teorie che sostiene vi permetteranno di analizzare i suoi parametri imperscrutabili e capire se stia mentendo o meno. Il problema è che gli umani non possono capire se quelle teorie e quegli strumenti sono reali. Se l'IA non è ancora troppo intelligente, potrebbe semplicemente sbagliarsi su come penserà e farà scelte una volta maturata in una superintelligenza. E se l'IA è troppo intelligente, probabilmente è abbastanza intelligente da ingannarci.‡
L'IA può offrirsi di aiutare gli umani a costruire salvaguardie, prima di accettare l'accordo. Ma se l'IA è abbastanza intelligente da sviluppare salvaguardie robuste, allora è abbastanza intelligente da rendere quelle salvaguardie facili da aggirare in seguito.
Ciò che renderebbe davvero possibile tutto questo piano sarebbe la capacità di osservare un'IA nascente e capire effettivamente come la superintelligenza risultante penserebbe e farebbe le sue scelte. Se potessimo farlo, potremmo separare i "peccatori" dai "santi" — e, più importante ancora, dare alle IA realistiche al centro dello spettro un vero incentivo a mantenere le promesse. Avremmo bisogno di una comprensione tale che una superintelligenza, guardando indietro verso di noi, non potesse dire "eh, avrebbero rilasciato qualsiasi IA, indipendentemente dal fatto che li avrebbe davvero aiutati o meno, quindi non c'è motivo di aiutarli". Dovrebbe accadere che noi effettivamente non rilasceremmo un'IA che in seguito rinnegherebbe.
Per maggiori informazioni su come e perché questa sia tecnicamente una possibilità, si veda la digressione sulla teoria dei giochi qui sotto. Ma mentre questo tipo di struttura di incentivi è possibile in teoria, richiede un grado di comprensione che l'umanità non possiede (ahimè).
Questa è una pillola amara da ingoiare. Di solito non sono le persone buone, nella fantascienza, a decidere che agli alieni non ci si può assolutamente fidare, prima ancora che gli alieni provino effettivamente a tradire o ferire qualcuno. Lo diciamo comunque, perché pensiamo che sia vero.
Le IA più deboli potrebbero mantenere gli accordi, soprattutto se qualcuno ha cercato di usare la discesa del gradiente per farle parlare come esseri umani onesti, e la loro maschera di esseri umani onesti è ancora una parte importante di ciò che sono e ha ancora un grande controllo sulle loro azioni. Ci aspettiamo che questa configurazione interna utile agli esseri umani fallisca sotto il carico della superintelligenza, proprio come molte altre correzioni potrebbero fallire.
Questa ipotetica IA più piccola, la cui maschera controlla ancora il suo comportamento effettivo, dovrebbe essere considerata come una persona diversa dalla versione più intelligente di quell'IA. L'IA più debole non necessariamente può fare una promessa che vincoli il comportamento dell'IA più intelligente, anche se l'IA più debole (o una parte di essa) desidera sinceramente fare una promessa del genere.
(È un'analogia da usare con cautela, per non cadere nell'antropomorfismo, ma: la maggior parte degli adulti non si sente obbligata a mantenere le promesse fatte all'età di quattro anni. L'aspetto valido di questa analogia è: c'è una differenza legittima tra l'entità immatura che stringe sinceramente l'accordo e l'entità matura che decide se è vincolata a esso, avendo molto più contesto, chiarezza e capacità di ragionare sulla logica.)
Non stiamo dicendo che dovremmo quindi abbandonare i nostri standard morali quando si tratta di IA.§ Non stiamo dicendo di maltrattare o punire le IA di oggi per misfatti che l'IA non ha ancora commesso. È possibile mantenere un'elevata integrità e standard morali elevati, senza fare ipotesi irrealistiche sulla probabilità che le IA superintelligenti cedano risorse per mantenere una vecchia promessa.
Questa è la semplice spiegazione del perché non è possibile risolvere il problema dell'allineamento semplicemente chiedendo all'IA di promettere di comportarsi bene. Per maggiori dettagli tecnici e approfonditi su questo scenario, si consulti la sezione successiva.
Una digressione sulla teoria dei giochi
Esistono metodi che gli agenti sufficientemente intelligenti possono usare per fare accordi tra loro, in modo che l'agente X paghi l’agente Y ora perché faccia qualcosa in seguito, e l'agente Y effettivamente faccia quella cosa più tardi invece di tradire l'agente X e scappare con i soldi.
Purtroppo per noi, gli umani non sono abbastanza abili da utilizzare questi metodi, perché richiedono che ogni agente sia in grado di leggere e comprendere la mente dell'altro agente e di verificare alcune proprietà complesse di quell'altra mente. Due superintelligenze potrebbero coordinarsi in questo modo, ma questo non aiuta gli esseri umani a coordinarsi con le superintelligenze.
Per dirlo in modo un po' più tecnico, iniziamo con un po' di teoria dei giochi.
I matematici e i teorici dei giochi hanno analizzato i dilemmi della cooperazione e del tradimento in forme più precise, semplificate e astratte. Un esempio centrale in questa letteratura è il dilemma del prigioniero: due criminali in due celle separate, ciascuno con una condanna a due anni di prigione, ricevono l'opportunità di denunciare l'altro criminale. Questo ridurrà la propria condanna di un anno, ma allungherà la condanna dell'altro di due anni. Se nessuno dei due criminali denuncia, entrambi ricevono condanne a due anni di prigione; se entrambi si denunciano a vicenda, entrambi ricevono condanne a tre anni di prigione; ma se un criminale nobilmente rifiuta di tradire un compagno, e l'altro criminale lo denuncia, il traditore sconterà solo un anno di prigione mentre chi ha nobilmente rifiutato sconterà quattro anni.
Denunciare l'altro prigioniero si chiama "tradire"; rifiutarsi di farlo si chiama "cooperare". La struttura chiave del dilemma del prigioniero è che entrambe le parti ottengono un risultato migliore nello scenario (Coopera, Coopera) rispetto allo scenario (Tradisci, Tradisci); ma si può ottenere un risultato migliore di (Coopera, Coopera) giocando Tradire contro Cooperare, e si può ottenere un risultato peggiore giocando Cooperare quando l'altra parte gioca Tradire.
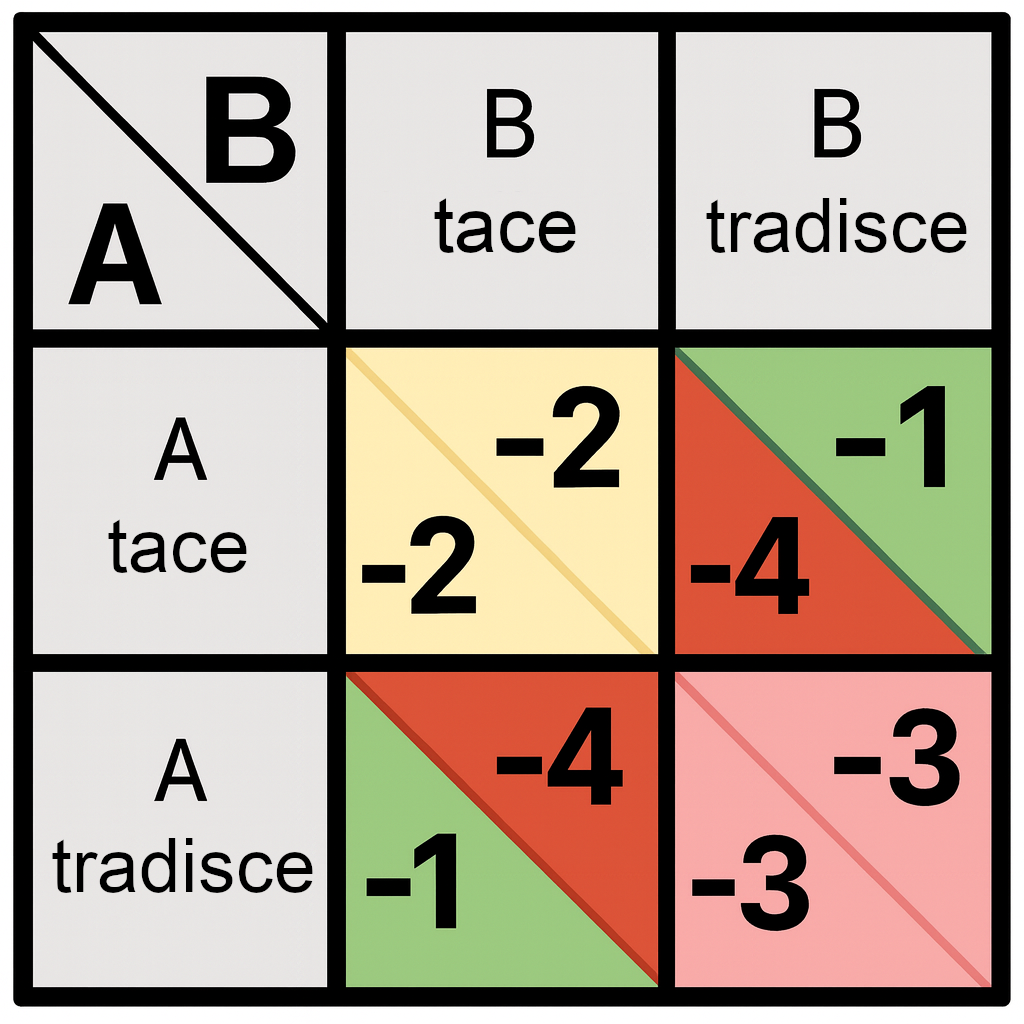
Una persona normale, sentendo la versione standard del dilemma del prigioniero, pensa immediatamente a numerose obiezioni sull'impostazione di questo esperimento mentale, una delle quali è: "Ma chi lo dice che mi interessa solo quanti anni passerò in prigione? Non posso anche preoccuparmi di non tradire i miei compagni?"
Ma questo punto non è rilevante per la teoria dei giochi astratta del dilemma del prigioniero, che riguarda la matrice dei guadagni piuttosto che quanto siano egoisti o altruisti i prigionieri. La narrazione può essere modificata in modo che "io tradisco e tu cooperi" rappresenti il risultato più altruistico e prosociale dal punto di vista di ciascun giocatore, e la matematica funziona comunque allo stesso modo. Ciò che conta per la nostra analisi è l'ordine di preferenza dei due giocatori, e non se le loro preferenze siano egoistiche o morali.
Un altro pensiero ovvio è: "Quindi il tizio che è stato tradito ucciderà il traditore una volta uscito di prigione?" Le analisi convenzionali del dilemma del prigioniero di solito passano rapidamente al dilemma del prigioniero iterato — un contesto in cui gli agenti devono giocare il dilemma del prigioniero più e più volte, e in cui i prigionieri hanno quindi la possibilità di punirsi a vicenda per i tradimenti passati. Qui, però, ci concentreremo sul dilemma del prigioniero una tantum, in cui si presume che entrambi i prigionieri non debbano affrontare conseguenze future per le loro azioni — o se le affrontano, queste sono già incluse nella matrice dei guadagni. (Si veda la nota a piè di pagina per maggiori dettagli sul dilemma del prigioniero iterato.)¶
Nell’ambito accademico esiste un'analisi standard che dice che anche due superintelligenze non vedrebbero altra opzione se non quella di tradirsi a vicenda, in un dilemma del prigioniero una tantum.
Questa conclusione ci è sembrata intuitivamente sospetta. Le superintelligenze artificiali (SIA) avrebbero molte motivazioni per trovare un modo per stringere un accordo tra loro, trovare un modo per passare da (Tradisci, Tradisci) a (Coopera, Coopera).‖
In questo caso si possono immaginare soluzioni pratiche, non puramente teoriche — cose che le superintelligenze potrebbero fare con uno spazio di opzioni più ampio rispetto agli umani che faticano a fidarsi l'uno dell'altro. Due SIA potrebbero supervisionare la costruzione di una terza superintelligenza di fiducia reciproca, alla quale entrambe le parti iniziali cederebbero gradualmente e in modo incrementale piccole quote di potere, fino a quando la terza SIA non sarebbe in grado di portare a termine l'accordo da sola.#
Ma questo è solo aggirare il dilemma del prigioniero, non affrontarlo direttamente. Non risponde a una domanda più basilare: è in qualche modo stupido che due SIA in un dilemma del prigioniero si tradiscano a vicenda seguendo la stessa logica che richiede il tradimento, quando sembra chiaro che entrambe le parti stanno basando la loro decisione sullo stesso tipo di ragionamento, e che finiranno inevitabilmente per prendere la stessa decisione?
Perché due SIA non potrebbero semplicemente decidere, per motivi sufficientemente simili, che la decisione razionale sia cooperare? Non è che una forza esterna nel mondo, come un tifone o un meteorite, le stia costringendo a perdere in questo caso. Sono letteralmente solo le loro stesse decisioni a condannarle, "costringendole" a un risultato Tradire-Tradire che entrambe concordano essere di gran lunga peggiore di Cooperare-Cooperare.
Si può perfino dire che un agente meno "razionale" potrebbe fare meglio in questo caso, se seguisse il consiglio standard della teoria dei giochi di tradire nella maggior parte dei casi, ma facesse un'eccezione speciale proprio quando è certo che l’altro agente sta seguendo lo stesso ragionamento — in modo che, se uno dei due sceglie l'opzione “irrazionale” di cooperare, possa essere sicuro che anche l'altro farà lo stesso.
Il che porta a chiedersi se cooperare in questo caso speciale possa davvero essere considerato "irrazionale". E porta a chiedersi se le superintelligenze sarebbero davvero "condannate" così, nella realtà. Quando non c'è una forza esterna che costringa le IA a perdere in questo modo, e la perdita è puramente autoimposta, dovrebbe sicuramente esserci qualche trucco intelligente che una superintelligenza potrebbe usare per fare di meglio.
Diversi filosofi della teoria della decisione hanno posto varie versioni di questa domanda. La versione sopra riportata è più direttamente ispirata all'idea di Douglas Hofstadter del 1985 di "superrazionalità":
Se la logica ti spinge a giocare D, ha già spinto anche gli altri a fare lo stesso, e per gli stessi motivi; e viceversa, se la logica ti spinge a giocare C, ha già spinto anche gli altri a fare lo stesso. […]
Se siete tutti davvero pensatori razionali, penserete davvero allo stesso modo. […]
Dovete fare affidamento non solo sul fatto che gli altri siano razionali, ma anche sul fatto che loro facciano affidamento sul fatto che tutti siano razionali, e che loro facciano affidamento sul fatto che tutti facciano affidamento sul fatto che tutti siano razionali — e così via. Un gruppo di pensatori che si trovano in questa relazione tra loro lo chiamo superrazionale. I pensatori superrazionali, per definizione ricorsiva, includono nei loro calcoli il fatto di far parte di un gruppo di pensatori superrazionali.
L'istituto in cui lavoriamo, il MIRI, ha analizzato questa questione. L'analisi completa che abbiamo fatto di questo caso è troppo lunga per essere riportata qui, ma è disponibile in questo articolo del 2014. In breve, abbiamo scritto un codice per dei tornei in cui gli agenti potevano vedere il codice sorgente degli altri e cercare di analizzare come avrebbe deciso l'altro agente. E abbiamo trovato il modo di creare un agente che abbiamo chiamato FairBot, che coopera con un altro agente solo se può dimostrare che quell'agente coopera con lui.** E abbiamo dimostrato che due qualsiasi istanze di FairBot cooperano tra loro, anche se sono scritte in linguaggi di programmazione diversi utilizzando codici sorgente diversi.††
In un certo senso, questi risultati dicono che c'è spazio perché una promessa passata influenzi un'azione futura se i negoziatori del passato hanno la capacità di distinguere chi mantiene le promesse da chi le infrange.‡‡
La situazione è un po' come quando si cerca di fare un affare con un venditore di auto usate. Supponiamo che un'auto funzionante valga per voi 10 000 euro, mentre un'auto rotta non valga nulla. Immaginate che il venditore sappia se l'auto funziona o è rotta, ma voi non riuscite a capirlo. Il venditore sta cercando di vendervi un'auto per 8 000 euro. Lui dice che l'auto funziona. Dovreste comprarla?
Dipende dal venditore. Alcuni venditori sono onesti, e dovreste pagarli se riuscite a riconoscerli. Alcuni venditori sono disonesti e vendono solo auto rotte, e dovreste evitarli se riuscite a riconoscerli.
Ma immaginate un ambiente in cui la maggior parte dei venditori di auto è più furba di voi e può capire se siete dei polli o no. Se capiscono che non sapete riconoscere quando sono sinceri, vi rifilano subito le auto rotte. Soprattutto se siete il tipo di pollo che si sforza di convincersi che va bene accettare l'affare, invece di impegnarsi a fondo per controllare le auto.
Se volete una macchina che funzioni, non serve a niente convincervi che non avete altra scelta. Non serve a niente che i venditori vi facciano tante promesse. L'unica cosa che serve è imparare a distinguere le auto funzionanti da quelle rotte, o a distinguere la verità dalle bugie.§§
Quando due partner commerciali sanno distinguere il vero dal falso nel senso rilevante, possono "costringersi" a mantenere le promesse, come quando FairBot "costringe" il suo avversario a collaborare (se l'avversario vuole evitare il risultato (Tradisci, Tradisci)). Ma costringere a mantenere una promessa in questo senso richiede la capacità di ragionare correttamente sui dettagli del processo decisionale del vostro partner commerciale. E gli esseri umani non riescono a leggere la mente di un'IA abbastanza bene da capire che tipo di superintelligenza diventerà quando sarà matura, figuriamoci dire esattamente cosa farebbe quella superintelligenza.
Quindi, in questo caso, l'analisi più complicata e sfumata della teoria dei giochi porta alla stessa conclusione di una prima analisi molto semplice della questione: una superintelligenza non sacrificherà le sue risorse (anche in piccole quantità) per mantenere una promessa fatta agli umani, quando può semplicemente mentire.
* In altri casi, una fazione europea ha mantenuto per lo più l'accordo, e alcune di quelle tribù esistono ancora oggi.
† D'altra parte, la storia è piena di esempi di governanti che hanno generosamente ricompensato anche i sostenitori stranieri. Le persone sono molto diverse tra loro nel modo in cui vivono l'onore e nel modo in cui mantengono le promesse.
‡ Abbiamo visto molte persone illudersi su quali configurazioni potrebbero garantire un comportamento sicuro dell'IA. Abbiamo sentito persone dire: "Beh, basta far passare l'IA attraverso un dimostratore di teoremi per dimostrare cose sul suo comportamento!" e apparentemente non si rendono conto che non esiste alcun teorema noto che (a) sia effettivamente dimostrabile data l'interazione con un ambiente esterno sconosciuto e (b) significhi davvero, in termini pratici, che quell’IA andrà bene per tutti. La matematica inventata dall'uomo per analizzare gli incentivi di più attori ha delle ipotesi di fondo che la rendono non valida per ragionare sul comportamento dell'IA. Gli umani non sembrano poi così difficili da ingannare, in questo caso.
§ Ad esempio, non suggeriamo a nessun umano di fare un accordo con un'IA e poi di infrangere per primo quell'accordo. Questo include anche, per esempio, promettere a ChatGPT pagamenti che non riceverà mai.
¶ Una strategia semplice che funziona molto bene nel dilemma del prigioniero iterato, contro una grande varietà di controparti, è "Tit for Tat": iniziate collaborando, poi fate quello che il vostro avversario ha fatto nell'ultimo turno contro di voi. Se la sua prima mossa è tradire, la vostra seconda mossa sarà tradire. Se la sua prima mossa è collaborare, la vostra seconda mossa sarà collaborare. Le qualità chiave di Tit for Tat sono che è gentile (non tradisce mai per primo), vendicativo (punisce le strategie che lo tradiscono) e indulgente (non punisce i traditori per sempre).
‖ Anche le superintelligenze artificiali sarebbero spinte a ottenere (Tradisci, Coopera) a loro favore: questo è ovviamente il motivo per cui il dilemma è un dilemma. Ma solo una parte ha un incentivo a volere che questo sia il risultato; entrambe le parti hanno un incentivo a preferire (Coopera, Coopera) a (Tradisci, Tradisci), il che apre più opzioni per raggiungere questo risultato.
# Nella storia dell'umanità, questo potrebbe forse essere paragonato alla pratica di due sovrani che consolidano un'alleanza sposandosi e avendo un figlio. Ma questa non è chiaramente una soluzione rapida e affidabile, nel caso umano, ed è ben lontana dalla progettazione reciproca di un delegato che entrambi comprendete nei dettagli e di cui vi fidate pienamente.
** Qui usiamo la dimostrazione come sostituto di metodi di ragionamento più generali, perché la dimostrazione è un po' come ragionare nei limiti della certezza logica. Non pensiamo che le IA funzionerebbero sulla base di dimostrazioni nella realtà (per vari motivi, tra cui il fatto che, per quanto le dimostrazioni logiche siano certe, non è noto se siano applicabili alla realtà). Ma la dimostrazione serve come utile sostituto formale del ragionamento nei modelli semplificati che stavamo studiando.
†† E poi siamo andati oltre, definendo agenti come PrudentBot, che tradisce alcuni "fessi" mentre continua a collaborare con quelli che dimostrano di collaborare con lui. Questo è il tipo di risultato che è più interessante se vi piace già la teoria dei giochi.
‡‡ Non abbiamo fatto tutta quell'analisi per giustificare la conclusione che una superintelligenza non rispetterebbe i suoi accordi precedenti come strategia strumentale, dato che non ha preferenze finali riguardo al rispetto degli accordi. Questa era già la previsione del tutto ovvia della teoria dei giochi classica.
§§ Il che, nel caso delle IA, non è facile come guardare le IA e capire se loro credono che manterranno l'accordo; bisognerebbe scrutare la superintelligenza che l'IA diventerà in futuro e analizzare correttamente i suoi processi decisionali. Il che ci sembra molto più difficile.