Интеллект постижим
В последние годы сфера ИИ продвинулась вперёд не благодаря углублению понимания интеллекта, а в поиске способов его «выращивать». Попытки понять сам интеллект годами заходили в тупик и приводили к застою. Но создание мощных ИИ увенчалось успехом. Поэтому некоторые задаются вопросом: не мираж ли сама идея «понимания интеллекта»? А вдруг нет никаких общих принципов, которые можно было бы понять? Или они чересчур странные, сложные и вовсе недоступные для людей?
Другие считают, что в человеческом разуме должно быть нечто особенное и мистическое, слишком священное, чтобы его можно было свести к сухим уравнениям. И раз интеллект всё ещё не понят, возможно, истинный разум происходит из этой непостижимой части человеческого духа.
Наш собственный взгляд гораздо прозаичнее. Интеллект — природное явление не хуже других. И, как и с много чем ещё в биологии, психологии и других науках, мы в самом начале пути к его пониманию.
Многим основным инструментам и концепциям современной психологии и нейробиологии всего несколько десятков лет. Заявление «У науки есть свои пределы, и, наверное, это один из них» может показаться скромным. Но представьте, что говорите кому-то, будто учёные через миллион лет будут понимать интеллект ненамного лучше, чем мы в 2025 году. В таком свете утверждение о непостижимости интеллекта звучит более высокомерно, чем обратное.
Нас этот вопрос заботит в основном потому, что от него зависит, сможет ли человечество однажды создать суперинтеллект, не рискуя вымиранием. В Главе 11 мы будем утверждать, что сегодняшняя область ИИ больше похожа на алхимию, чем на химию. Но возможна ли в принципе «химия ИИ»?
Сейчас у нас нет необходимых научных знаний. Поэтому не так-то просто доказать, что «химия ИИ» возможна! Как будет выглядеть зрелая наука об ИИ, мы можем лишь догадываться. Учитывая, как далеки мы от этого сегодня, вероятно, многие наши концепции по мере прогресса понимания придётся уточнить или заменить.
Но мы всё равно думаем, что интеллект в принципе постижим. Мы не считаем это особо сильным утверждением, хотя последние десятилетия показывают, что просто тут не будет.
У нас есть четыре основные причины так думать:
Заявления о непостижимости в науке почти всегда оказывались неверными.
Видно, что у интеллекта есть структура и закономерности.
В человеческом интеллекте есть много того, что в принципе должно быть постижимо, но ещё не понято.
Уже есть некоторый прогресс.
Заявления о непостижимости в науке почти всегда оказывались неверными
Явления часто кажутся пугающими и очень таинственными, когда человечество их ещё не понимает. Может быть трудно представить или прочувствовать, каково будет однажды это понимание обрести.
Когда-то среди философов и учёных была широко распространена вера в витализм — идею, что биологические процессы никогда не удастся свести к простой химии и физике. Жизнь казалась чем-то особенным, принципиально отличающимся от обычных атомов и молекул, гравитации и электромагнетизма.*
Всю историю такая ошибка встречалась на удивление часто. Люди склонны быстро заключать, что таинственное сегодня таинственно по своей сути. Что оно непознаваемо в принципе.
Если, посмотрев на ночное небо, вы видите лишь поле мерцающих огней, природа и законы которых неизвестны... то с чего верить, что вы когда-нибудь сможете их познать? С чего этому аспекту будущего быть предсказуемым?
Ключевой урок истории: наука может справляться с такими глубокими загадками. Иногда тайна раскрывается быстро. Иногда на это уходят сотни лет. Но кажется всё менее вероятным, что какие-либо повседневные аспекты человеческой жизни, такие как интеллект, в принципе невозможно понять.
Видно, что у интеллекта есть структура и закономерности.
Представьте, что вы живёте тысячи лет назад. Даже такое явление, как «огонь», казалось тогда непостижимой тайной. Как бы вы догадались, что однажды люди смогут его понять?
Одна наводка: огонь — не единичное событие. Он горит много где и всегда похоже. Это отражает скрытую в реальности стабильную, регулярную и компактную сущность «огня». У разных возможных конфигураций материи разная химическая потенциальная энергия. Нагревание позволяет этим конфигурациям распадаться и превращаться в новые, более прочно связанные, с меньшей потенциальной энергией. Разница высвобождается в виде тепла. Вы можете разжечь огонь не один раз. Значит за ним стоит некий повторяющийся феномен, который можно изучать. В плане того, сколько можно понять и предсказать, «Огонь» не похож на «точные выигрышные номера прошлой лотереи».
Аналогично, если вы посмотрите на ночное небо, звезда там не одна. Даже у планет, отличающихся от других «звёзд», есть с ними нечто общее с точки зрения знаний, нужных для их понимания.
У наших предков не было опыта успешного объяснения огня как химии. Они могли не быть уверены в своей способности когда-нибудь понять звёзды. Но мы уже постигли природу огня, звёзд и многого другого. Мы можем извлечь тонкий урок, сверх «Ну, мы поняли то, значит, поймём и всё остальное в будущем». Он в том, что повторению соответствует закономерность. Если явление происходит часто, ему есть причина.
Интеллект демонстрирует схожие закономерности. Они указывают, что его можно постичь. Например, интеллект есть у каждого человека. Эволюция смогла создать его путём слепого перебора геномов. Видно, что схожие комбинации генов могут успешно справляться с множеством разных задач. Гены, позволившие человеческому мозгу обтёсывать рубила, открыли нам и копья и луки. Примерно те же самые гены породили мозг, который изобрёл сельское хозяйство, огнестрельное оружие и ядерные реакторы.
Если бы у интеллекта не было структуры, порядка или закономерности, если бы нельзя было найти в нём паттерны, одно животное могло бы предсказывать или изобретать только что-то одно. Мозг пчелы специализирован для ульев; он не может ещё и строить плотины. Могло бы случиться, что людям требовалась бы такая же специализация для каждой решаемой задачи. Могло бы быть так, что для постройки ядерных реакторов нам пришлось бы отрастить особые, специализированные участки мозга. Обнаружь нейробиологи такое, у них были бы основания подозревать, что нет никаких глубоких принципов интеллекта, которые можно понять. Что для каждой задачи принципы свои, отдельные.
Но человеческий мозг не такой. Мы знаем, мозг, предназначенный для обтёсывания рубил, способен изобретать ядерные реакторы. Значит, в основе лежит некий паттерн, который применяется снова, и снова, и снова.
Интеллект — не хаотичное, непредсказуемое и одноразовое явление, как точные выигрышные номера прошлой лотереи. Тут есть некая закономерность, которую предстоит понять.
Мы ещё многое не поняли о человеческом интеллекте, что должно быть постижимо в принципе
Современная наука многое знает о строении и поведении отдельных нейронов у людей. И мы многое можем сказать об обыденной бытовой психологии, вроде «Боб пошёл в магазин один, потому что злился на Алису». Но в нашем понимании зияет огромная пропасть между этими двумя уровнями описания.
Мы очень мало знаем о многих когнитивных алгоритмах мозга. Мы имеем очень приблизительное представление о корреляции разных функций с областями мозга, но и близко не подошли к механистическому описанию его работы.
Наглядная иллюстрация того, что тут пропущен уровень абстракции — наши высокоуровневые нейробиологические модели выдают гораздо худшие прогнозы, чем можно было бы получить, моделируя нейроны. Значит, наше механистическое понимание других людей неполно.
Некоторая потеря информации, наверное, неизбежна. Но в хорошей модели её было бы гораздо меньше. «Понимание» работы дифференциала автомобиля не выдаст такие же точные предсказания его работы, как дала бы симуляция на атомарном уровне. Ведь, например, зубья шестерёнок могут износиться и проскальзывать. Но всё же оно даёт некоторые очень точные прогнозы. И легко отличить, что модель должна предсказывать (например, как будут вращаться шестерни при нормальном сцеплении), и что не должна (например, что произойдёт, когда зубья износятся).
Но с чего нам считать, что такая степень моделирования возможна для человеческого разума? А вдруг он для этого слишком хаотичен. Вдруг тут либо моделировать нейроны, либо никаких вам точных прогнозов.†
В пользу того, что дело обстоит не так, говорит то, что даже ваша мама может предсказать ваше поведение точнее, чем лучшие формальные модели мозга. Значит, в человеческой психологии определённо есть некая структура, которую можно изучить неявно, не моделируя ничьи нейроны. Просто её ещё не сделали явной.
Более конкретное свидетельство: некоторые люди с амнезией склонны дословно повторять одну и ту же шутку много раз. Это указывает на некоторую закономерность в мозге конкретного человека. Видимо, он подсознательно выполняет определённое вычисление (основанное, возможно, на обстоятельствах, присутствии медсестры, его воспоминаниях, истории, желании нести радость и казаться умным), и оно достаточно стабильно при малых изменениях.
Если в мыслительных процессах человека столько порядка, их должно быть возможно изучить. Изучить механизм принятия решений, разобраться в работе мозга достаточно глубоко, чтобы сказать:
«Ага, вот эти нейроны отвечают за желание нести радость, а те — за желание казаться умным. Тут генерируются возможные мысли при виде вошедшей в комнату медсестры, а там — идея „рассказать анекдот“. А вот как эти и те нейроны с ней взаимодействуют, и мысль выдвигается на передний план в широком контексте. А вот параметры того, как контекст влияет на доступ к памяти. А если проследить за вот этим, ясно, откуда идея обвести взглядом комнату. А на стене висит картина с парусником, можно увидеть, как она активирует концепт «парусника» в группе нейронов тут. Проследите это в обратную сторону до поиска в памяти, и станет ясно, почему пациент в итоге шутит про парусники».
Правильное объяснение звучало бы не совсем так. Но закономерность простого макроскопического наблюдения («одна и та же шутка каждое утро») ясно указывает — тут есть воспроизводимое вычисление, а не только непроглядный случай. (Это, конечно, говорит и здравый смысл: если бы мозг был чисто случайным, мы бы не могли функционировать.)
Уже есть некоторый прогресс
Это главная причина, почему мы уверены: об интеллекте можно ещё многое узнать. Если открыть старые книги вроде The MIT Encyclopedia of the Cognitive Sciences или Artificial Intelligence: A Modern Approach (2-е издание), написанные до того, как область ИИ была пожрана современными методами «глубокого обучения» (выращивания ИИ), можно получить неплохое представление о том, как решаются разные задачи мышления. Не всё это уже переписано простым языком для широкой аудитории или массово преподаётся студентам. Непопуляризованного накопилось гораздо больше.
Возьмём научный принцип: при прочих равных следует отдавать предпочтение более простым гипотезам. Что именно здесь значит «простая»?
«Моя соседка — ведьма. Это сделала она!» для многих звучит проще, чем описывающие электричество уравнения Максвелла. В каком смысле «проще» уравнения?
А что значит для свидетельств «подходить» гипотезе, а гипотезе — «объяснять» их? Как мы соотносим ценность простоты гипотезы и её объяснительной силы? «Моя соседка — ведьма. Это сделала она!» вроде бы может объяснить кучу всего! Но многие (и правильно) чувствуют, что это плохое объяснение. Причём частично именно потому, что колдовство «объясняет» слишком многое.
Есть ли общие принципы выбора между гипотезами? Или только сотня разных инструментов под разные задачи? И если второе, как человеческий мозг вообще умудряется изобретать эти инструменты?
Есть ли язык, на котором можно описать любую гипотезу, что мозг или компьютер могли бы успешно использовать?
Такие вопросы поначалу могут казаться неразрешимыми и философскими. Но на самом деле всё это решено и хорошо изучено информатикой, теорией вероятности и теорией информации. Они дают ответы вроде «минимальная длина сообщения», «индукция Соломонова» и «отношение правдоподобия».‡
Заметим и что уже существуют совершенно понятные, но сверхчеловеческие в отдельных областях ИИ. Мы понимаем все ключевые принципы Deep Blue. Его написали вручную, так что можно легко просмотреть отдельные части его кода, увидеть, что делает конкретный фрагмент и как он связано со всем остальным.
Когда речь про LLM вроде ChatGPT, неочевидно, что вообще может существовать полное и краткое описание, как они работают. Эти нейросети очень большие и могут что-то делать по многим сонаправленным причинам сразу. Если, например, механизм этого поведения повторён внутри LLM тысячи раз.
ChatGPT может остаться сложной для понимания учёных даже после десятилетий изучения. Но из её существования не следует, что работающий интеллект обязан быть таким же «грязным». Только что пытаться масштабировать что-то вроде ChatGPT до суперинтеллекта — крайне плохая идея. В следующих главах книги мы подробнее обсудим, почему.
То, что какой-то конкретный разум устроен хаотично, не значит, что интеллект невозможно понять. Не значит даже, что никогда не получится понять ChatGPT. Если очень пристально смотреть на сотню горящих поленьев, видно: нет двух, что пылают совершенно одинаково. Огонь распространяется по-разному, угольки летят куда попало, всё очень хаотично. Посмотри на полено огнеупорным микроскопом — увидишь ещё больше головокружительных подробностей. Легко представить древнего философа, который, наблюдая этот хаос, решит: огонь никогда не будет полностью понят.
И он даже мог бы быть прав! Мы, возможно, никогда не сумеем посмотреть на полено и точно сказать, какой именно кусочек дерева станет первым угольком, унесённым на запад. Но древний философ сильно ошибся бы, решив, будто мы никогда не поймём, что такое огонь, почему он возникает, не создадим его в контролируемых условиях и не обуздаем его с большой выгодой.
Точный узор угольков не слишком упорядочен. Воспроизвести его сложно. Зато на более абстрактном уровне жёлто-оранжево-красная мерцающая горячая штука — повторяющаяся в мире закономерность, которую человечество сумело понять.
Аргументы из «Если кто-то его сделает, все умрут» мало зависят от сегодняшних технических подробностей. «Люди продолжают делать всё более умные компьютеры и не контролируют их. Если сделают очень умную неконтролируемую штуку, мы в итоге умрём.» — не слишком эзотерическая идея. Но полезно понимать, что тут уже есть немало знаний, хоть тайн и неизвестного в этой области не счесть.
Ключевые аргументы книги не зависят от того, понятен ли интеллект в принципе. Поэтому мы не вдавались в пересказ подробных мыслей об этом из существующей литературы. Даже если никто никогда не сможет постичь тайны сверхчеловеческого машинного интеллекта, он всё равно может нас убить.
Этот вопрос обретёт значимость в основном при решении — что делать после остановки самоубийственной ИИ-гонки.
Станет важно, что интеллект, вероятно, можно понять. Значит, в принципе, умные люди могли бы развить зрелую науку об интеллекте и найти решение задачи согласования ИИ.
Конечно, важно ещёи то, что современному человечеству до этого достижения очень далеко. Но сам факт, что оно возможно, влияет на то, как нам следует выбираться из этой передряги. Подробнее об этом позже, в расширенном обсуждении к Главе 10.
«Очевидные» идеи приходят не сразу
Новые озарения в сфере ИИ даются с трудом, даже если, оглядываясь назад, мы считаем их простыми и очевидными. Это важно понимать, ведь, скорее всего, понадобится много открытий, чтобы область развилась как надо. Какими бы простыми они ни казались задним числом, на них могут уйти десятилетия упорного поиска.
Проиллюстрируем это несколькими озарениями, без которых современные ИИ не работали бы.
Например, если вы немного умеете программировать, то можете прочитать главу 2 этой книги и подумать, что «градиентный спуск» — это же так просто, можно взять и написать. Но если вы так сделаете, то, скорее всего, быстро столкнётесь с каким-нибудь багом. Может, ваша программа вылетит с ошибкой переполнения числа, потому что один из весов стал слишком большим.
В двадцатом веке никто не знал, как заставить градиентный спуск работать в нейросети с несколькими промежуточными слоями между входом и выходом. Чтобы избежать проблем, нужны были всякие хитрые приёмчики, например, инициализировать все веса особым образом, чтобы они не становились слишком большими. Недостаточно было просто задавать всем весам случайные значения от 0 до 1 (или со средним 0 и стандартным отклонением 1). Приходилось ещё и разделить всё на константу, подобранную так, чтобы числа на следующем слое при обучении тоже не разрастались.
У градиентного спуска появляются проблемы при работе со сложными формулами с множеством шагов, или «слоёв». Деление исходных случайных чисел на константу — одна из основных идей, без которых «глубокое обучение» невозможно. Этот приём изобрели только через шесть десятилетий после изобретения нейросетей в 1943 году.
Идею использовать математический анализ для подстройки параметров впервые обсудили в 1962 году. А впервые применили к нейросетям с более чем одним слоем в 1967 году. По-настоящему популярной она стала только после выхода статьи 1986 года (одним из её соавторов был Джеффри Хинтон, это одна из причин, почему его называют «крёстным отцом ИИ»). Но заметьте, что более общую идею использования матанализа для движения в направлении правильного ответа дифференцируемой задачи (например, вычисления квадратного корня) изобрёл Исаак Ньютон.
Вот ещё одна важная хитрость. В книге мы даём такой пример операций градиентного спуска: «Я умножу каждое входное число на вес из первого вектора. Затем прибавлю его к весу из второго вектора. Затем заменю его нулём, если оно отрицательное. И так далее...»
Этот список операций приведён не случайно. Умножение, сложение и «замена нулём, если число отрицательное» — это, по сути, три важнейшие операции нейросети. Первые две составляют «матричное умножение», а последняя вносит «нелинейность». Так сеть получает возможность обучаться нелинейным функциям.
Формула для «замены нулём, если число отрицательное»: $$y \= \mathrm{max}(x, 0)$$. Это «выпрямленная линейная функция» (rectified linear unit, ReLU).§ Изначально же пытались использовать формулу «сигмоиды»:
$$\frac{e^x}{1 + e^x}$$
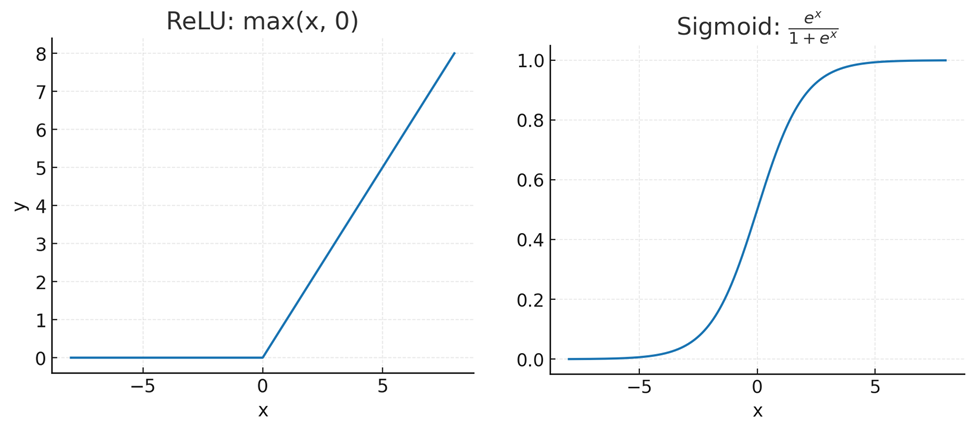
Были веские причины предполагать, что более сложная «сигмоида» сработает! Она плавно и логично приводит выходные значения в диапазон от 0 до 1. И у неё есть полезные связи с теорией вероятностей! Даже некоторые современные глубокие нейросети кое-где используют что-то вроде сигмоиды. Но если вам нужна только нелинейность, ReLU работает гораздо лучше.
Проблема сигмоиды: из-за неё у многих выходных значений нередко получаются крошечные градиенты. А если большинство их очень малы, градиентный спуск перестаёт работать... если только не знать современный приём: увеличивать шаги, когда крошечные градиенты постоянно указывают в одном направлении. (Насколько нам известно, этот трюк был впервые предложен Джеффри Хинтоном в 2012 году.)
Идеи «уменьшайте исходные случайные числа, чтобы суммы их произведений не становились огромными», «используйте max(x, 0) вместо сложной формулы» и «делайте шаги побольше, когда крошечные градиенты постоянно указывают в одну сторону» могут показаться на удивление простыми. Слишком простыми, чтобы на их открытие ушли десятилетия. Ведь для программиста, который во всём этом разбирается, они задним числом очевидны. Это важный урок о реальном устройстве науки и инженерии.
Даже когда у инженерной проблемы есть простое и практичное решение, исследователи часто находят его только после десятилетий проб и ошибок. Нельзя надеяться, что ответ найдут, как только он станет важным. Нельзя надеяться, что его найдут в ближайшие два года. Даже если задним числом решение кажется очевидным, вся область может топтаться на месте десятилетиями.
Мы тут немного забегаем вперёд Главы 2. Но этот урок стоит запомнить для Части III, в которой мы будем обсуждаем, насколько человечество не готово к вызову суперинтеллекта.
Если цена тому, что безумные изобретатели неловко тыкаются наугад в неразвитой области — смерть всех на Земле, мы не должны позволять им продолжать. Они будут возражать, что у них нет способа найти простое и надёжное решение, если не позволить им несколько десятилетий проб и ошибок. Они скажут, что нереалистично ожидать, будто они найдут ответ без этого.
Надеюсь, всем, кроме самих безумных изобретателей, очевидно: если эти утверждения верны, их попытки надо пресечь. Но к этой теме мы вернёмся в Части III, после того как до конца обоснуем, что у суперинтеллекта будут средства, мотив и возможность уничтожить человечество.
* Как выразился выдающийся физик лорд Кельвин в 1903 году: «Современные биологи вновь твёрдо принимают идею о существовании чего-то за пределами простых гравитационных, химических и физических сил; и это неизвестное — жизненный принцип». Источник: Сильванус Филлипс Томпсон, «Жизнь лорда Кельвина» (Американское математическое общество, 2005).
† Да что там, может, даже нейронные симуляции ненадёжны. Если, скажем, поведение человека сильно зависит от температуры.
‡ Юдковский подробнее писал об этом в своём блоге, см. «Что такое свидетельство?», «Сколько свидетельств понадобится?» и «Бритва Оккама».
§ Новые архитектуры используют более сложные функции. Например, Llama 3.1, которую мы опишем ниже, использует функцию «SwiGLU», сложную формулу, которую мы здесь приводить не будем. Её создатель сам не знает, почему она работает, и пишет: «Мы не предлагаем объяснения, почему эти архитектуры, по-видимому, работают. Мы приписываем их успех, как и всё остальное, божественной благодати».