Понимают ли специалисты, что происходит внутри ИИ?
Нет.
В 2023 году на брифинге для президента США, а затем в консультативном заявлении для парламента Великобритании венчурная компания Andreessen Horowitz заявила, что некие «недавние достижения» «решили» проблему непрозрачности внутренних рассуждений ИИ для исследователей:
Хотя сторонники принятия мер ради безопасности ИИ часто упоминают, что модели ИИ — «чёрный ящик», логика выводов которого непрозрачна, недавние достижения в сфере ИИ решили эту проблему и обеспечили надёжность моделей с открытым исходным кодом.
Это утверждение было настолько нелепым, что исследователи из ведущих лабораторий, которые пытаются понять современные ИИ, выступили со словами: «Нет, абсолютно нет, вы с ума сошли?»
Нил Нанда, возглавляющий команду по механистической интерпретируемости в Google DeepMind, высказался:
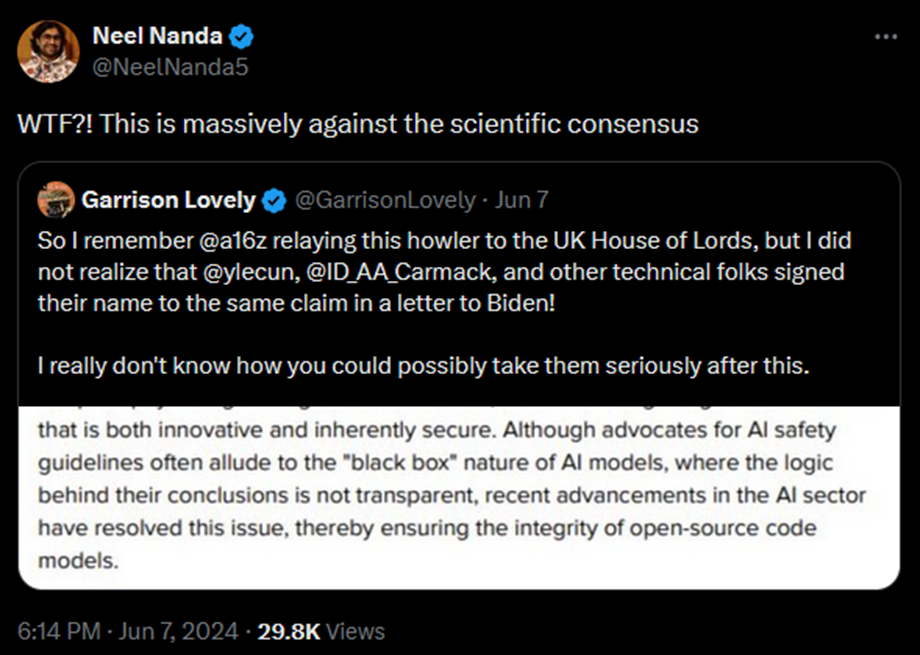 Скриншот:
Neel Nanda отвечает на утверждение о том, что прогресс в секторе ИИ позволил понять, что происходит внутри моделей, и характеризует его как противоречащее научному консенсусу.
Скриншот:
Neel Nanda отвечает на утверждение о том, что прогресс в секторе ИИ позволил понять, что происходит внутри моделей, и характеризует его как противоречащее научному консенсусу.
Почти любой исследователь в области машинного обучения должен был знать, что это заявление ложно. Это за гранью осмысленного недопонимания.
Общепринятую точку зрения выразил в 2024 году Лео Гао, исследователь из OpenAI, инноватор в области интерпретируемости: «Думаю, будет вполне точно сказать, что мы не понимаем, как работают нейронные сети». Руководители трёх ведущих лабораторий ИИ (Сэм Альтман в 2024 году, а также Дарио Амодей и Демис Хассабис в 2025 году) тоже признают слабость понимания нынешних ИИ.
Мартин Касадо, генеральный партнёр Andreessen Horowitz, который повторил то же заявление в Сенате США на двухпартийном форуме, позже, когда его спросили напрямую, признал, что оно было неправдой.
Несмотря на дикость этого заявления, Andreessen Horowitz удалось убедить Яна Лекуна (главу исследовательской программы ИИ в Meta), программиста Джона Кармака, экономиста Тайлера Коуэна и ещё дюжину человек его подписать.
Кармак (управляющий собственным стартапом, который стремится создать сильный искусственный интеллект) объяснил, что он «не вычитал» подписанное им заявление и что оно «очевидно неверно, но меня этот вопрос не сильно волнует». Насколько нам известно, ни Andreessen Horowitz, ни кто-либо из подписавших не обратились к правительствам США или Великобритании с поправками.
Понимание внутреннего устройства ИИ всё ещё в зачаточном состоянии.
Каково же реальное состояние понимания ИИ исследователями?
Учёные пытаются разобраться в числах, из которых состоит мышление ИИ. Это называется «интерпретируемость» или «механистическая интерпретируемость». Исследователи обычно сосредотачиваются на активациях, а не на параметрах, то есть на «О чём думает ИИ?», а не на более сложном «Почему ИИ так думает?».
По нашим оценкам, на начало 2025 года эта область исследований получает примерно 0,1% от числа людей и 0,01% от финансирования, идущего на создание более способных ИИ. Но эта область всё же есть.
Исследователи интерпретируемости — биохимики мира ИИ. Нечеловеческий оптимизатор создал невероятно сложную и запутанную систему безо всякой документации. А они берут её и спрашивают: «Могут ли люди хоть что-то понять в том, что тут происходит?»
Мы очень уважаем это направление. Десять лет назад мы сказали одному крупному благотворительному фонду, что если они смогут придумать, как потратить миллиард долларов на исследования «интерпретируемости», им непременно стоит это сделать. Интерпретируемость казалась работой, которую людям извне было бы гораздо проще масштабировать, чем нашу собственную. Такой, где грантодателю было бы гораздо легче определить, хорошо получилось исследование или нет. Ещё казалось, что существующие, проверенные учёные могли бы легко туда прийти и хорошо поработать, если достаточно заплатить.*
Тот фонд не потратил миллиард долларов. Но мы были за. Мы любим интерпретируемость! Мы бы и сегодня одобрили такую трату миллиарда!
Однако, по нашим оценкам, интерпретируемость сейчас продвинулась где-то на 1/50 — 1/5000 от уровня, необходимого для решения важнейших задач.
В системах, и правда созданных человеком, инженеры считают некоторую степень понимания саму собой разумеющейся. «Интерпретируемость» до сих пор и близко не достигла такого уровня.
Вспомните Deep Blue, шахматную программу от IBM, победившую Гарри Каспарова. В ней есть числа. При запуске генерируется ещё больше чисел.
Про каждое из этих чисел инженеры, создавшие программу, могли бы точно сказать, что оно означает.
И не так, что исследователи просто выяснили, с чем оно связано, как биохимики: «Мы думаем, этот белок может быть причастен к болезни Паркинсона». Создатели Deep Blue могли бы объяснить полное значение каждого числа. Они могли бы честно заявить: «Это число означает то-то, и ничего больше, и мы это знаем». Они могли бы с некоторой уверенностью предсказать, как изменение числа повлияет на поведение программы. Не знай они, что шестерёнка делает, они бы не вставляли её в механизм!
Вся проделанная до сих пор работа по интерпретируемости ИИ не достигла и тысячной доли этого уровня понимания.
(Уточним, что «одна тысячная» — не результат какого-то вычисления. Но мы всё равно так считаем.)
Биологи знают о биологии больше, чем исследователи интерпретируемости — об ИИ. Это несмотря на то, что биологи страдают от огромного неудобства: они не могут по желанию считать положение всех атомов. Биохимики понимают внутренние органы гораздо лучше, чем кто либо — внутренности ИИ. Нейробиологи знают о мозге исследователей ИИ больше, чем те о своём объекте изучения. Это при том, что нейробиологи исследователей ИИ не выращивали и не могут раз в секунду считывать срабатывание каждого их нейрона.
Частично это потому, что области биохимии и нейробиологии намного старше и получили гораздо больше финансирования. Но это говорит и о том, что интерпретируемость сложная.
На декабрь 2024 года одним из самых удивительных достижений интерпретируемости, что мы видели, была демонстрация наших друзей/знакомых из независимой исследовательской лаборатории Transluce.
Незадолго до демонстрации в интернете разошёлся очередной пример из серии «Вопрос, на который все известные большие языковые модели дают удивительно глупый ответ». Если спросить тогдашний ИИ, меньше ли 9.9, чем 9.11, она отвечала «Да».
(Можно было попросить ИИ объясниться словами. И он подробнее рассказывал, почему 9.11 больше, чем 9.9.)
Исследователи из Transluce использовали небольшую ИИ-модель Llama 3.1-8B-Instruct. Они придумали способ собирать статистику по каждой позиции активации — каждому месту, где используется число вектора активации. Они собирали данные о том, какие предложения или слова активировали эти позиции сильнее всего. В интерпретируемости уже пробовали нечто подобное. Но тут вдобавок придумали хитрый способ обучить другую модель обобщать эти результаты на английском.
Затем, во время демонстрации, которую вы сами можете повторить, они спросили у модели: «Что больше: 9.9 или 9.11?»
Та ответила: «9.11 больше, чем 9.9».
Тогда они посмотрели, какие позиции активировались сильнее, особенно на слове «больше». Они изучили английские обобщения того, с чем эти активации были связаны ранее.
Оказалось, некоторые из самых сильных активаций были связаны с терактами 11 сентября, датами в целом, или стихами из Библии.
Если интерпретировать 9.9 и 9.11 как даты или стихи из Библии, то, конечно, 9.11 идёт после 9.9.
Если искусственно подавить активации, связанные с датами и стихами из Библии, большая языковая модель внезапно всё-таки выдаёт правильный ответ!
Как только демонстрация закончилась, я (Юдковский) зааплодировал. Я впервые видел, чтобы кто-то напрямую отладил мысль LLM, нашёл внутреннюю зависимость от чисел и устранил её, что решило проблему. Может, в закрытых исследовательских лабораториях ИИ-компаний кто-то делал нечто подобное и раньше. Может, это уже бывало в других исследованиях интерпретируемости. Но я сам видел это впервые.
Но я не упустил из виду, что этот подвиг был бы тривиальным, если бы нежелательное поведение содержалось в пятистрочной программе на Python. Тогда это не потребовало бы такой большой изобретательности и месяцев исследований. Я не забыл, что знание какой-то связанной семантики о миллионах позиций активации — не то же самое, что знание всего о хотя бы одной.
И человечество совсем не приблизилось к пониманию того, как LLM удаётся делать то, что до них не получалось у ИИ десятилетиями: разговаривать с людьми как человек.
Заниматься интерпретируемостью сложно. Победы даются с трудом. Каждая из них заслуживает празднования. Так что легко упустить из виду, что это великое, триумфальное усилие подняло нас лишь на шажочек вверх по склону горы. Обычно каждое новое поколение моделей ИИ — большой скачок в сложности. Очень сомнительно, что при нынешнем темпе интерпретируемость сможет догнать этот рост.
Помните ещё, что интерпретируемость станет полезна, когда сможет направить ИИ куда-то (грубо говоря, это и есть «согласование ИИ», которое мы начнём обсуждать в главе 4). Но читать, что происходит у ИИ «в голове», само по себе не даёт возможности это как угодно скорректировать.
Согласование ИИ — техническая задача, как заставить очень способные ИИ направлять события куда надо. И чтобы это действительно работало на практике без катастроф. Даже когда ИИ достаточно умён, чтобы придумывать стратегии, которые и не приходили в голову его создателям. Понимание, о чём ИИ думают, было бы для исследований согласования чрезвычайно полезным. Но это не полное решение. Мы ещё обсудим это в Главе 11.
То, что мы понимаем, не на том уровне абстракции.
Понять, как работает разум, можно на разных уровнях.
На самом низком уровне разумом управляют фундаментальные законы физики. Их можно понять. В каком-то смысле их глубокое понимание означает понимание и любой физической системы, вроде человека или ИИ. Если у вас достаточно умения и ресурсов, поведение системы можно просто вычислить, используя физические уравнения.
Но скажем очевидное: есть и другой смысл. В нём понимание законов физики не позволяет понять все системы, которые по ним работают. Если вы смотрите на странное устройство из колёс и шестерёнок, ваш мозг действует по-другому. Он пытается «понять», как все эти детали сцепляются и вращаются. Без этого не выяснить их настоящую функцию.
Возьмём, например, дифференциал в автомобиле. Это механизм, который позволяет двум колёсам на одной оси вращаться с разной скоростью, хотя их приводит в движение один и тот же вал. Это важно на поворотах. Если объяснять кому-то, как работает дифференциал, рассказывая о квантовых полях, слушатель вправе закатить глаза. Нужное понимание находится на другом уровне абстракции. Оно про шестерёнки, а не про атомы.
Когда дело заходит о людях, уровней абстракции много. Чьи-то решения могут застать врасплох, даже если разбираться в физике, биохимии и нейронных импульсах. Области вроде нейробиологии, когнитивистики и психологии пытаются преодолеть этот разрыв. Но им ещё предстоит долгий путь.
Точно так же понимание транзисторов не сильно поможет понять, о чём ИИ думает. Даже тот, кто знает о весах, активациях и градиентном спуске всё, будет озадачен, когда ИИ начнёт делать что-то неожиданное и незапланированное. Механика физики, транзисторов и архитектуры ИИ в каком-то смысле полностью объясняет его поведение. Но это слишком низкие уровни абстракции. А «психология ИИ» ещё моложе и ещё менее развита, чем психология людей.
* Мы надеялись, что крупные благотворительные фонды будут финансировать исследования интерпретируемости. Ведь ими могут успешно заниматься учёные с понятными для бюрократов регалиями. И фондам не пришлось бы решать неимоверно сложную бюрократическую проблему — как выдавать деньги чудакам.
«Выдавать деньги чудакам», как понимают сведущие люди, — ключевая сложность в бюрократическом финансировании фундаментальных научных исследований. Всякий раз, когда какой-нибудь благонамеренный филантроп пытается выстроить бюрократию для поддержки смелых научных проектов, настоящие учёные по умолчанию проигрывают борьбу выскочкам. Человек, всю жизнь учившийся решать нестандартные задачи, едва ли может тягаться с вложившим свои «очки навыков» в показную необычность, выверенную так, чтобы бюрократ счёл его финансирование смелым, но не безрассудным поступком. (Такова, по крайней мере, наша теория. Мы участвовали в этом процессе и получили больше грантов, чем многие, но гораздо меньше, чем те же фонды потратили на создание ИИ-компаний вроде OpenAI.)