Как работает Llama 3.1 405B
Ниже приведено обещанное в книге более подробное описание LLM под названием Llama 3.1 405B. Оно предназначено для любопытных, а также для того, чтобы по-настоящему понять, в какой степени современные ИИ скорее «выращивают», чем создают. (См. также: Какая польза от знаний об LLM?)
Это весьма подробное описание. Мы будем предполагать (только здесь, в большей части онлайн-дополнения мы этого не делаем), что у вас есть некоторая техническая подготовка. Но мы не будем ожидать каких-то специальных знаний в области ИИ. Если вы начали читать этот раздел и не находите его ценным, можете пропустить.
Разработчики обычно не публикуют код и детали устройства самых мощных языковых моделей. Но есть исключения. На момент написания книги в конце 2024 года одной из самых мощных систем с открытой архитектурой и весами была Llama 3.1 405B от ИИ-подразделения Meta. «405B» означает 405 миллиардов параметров в архитектуре — 405 миллиардов весов.
Почему мы разбираем именно её? Llama 3.1 405B — модель с «открытыми весами»*. Это значит, вы можете скачать себе 405 миллиардов непостижимых чисел. В комплекте идёт гораздо меньший по размеру (и написанный человеком) каркас кода, что производит с ними вычисления, запуская ИИ. Это даёт нам некоторую уверенность в знаниях о её устройстве.†
Итак! Поговорим об организации этих 405 миллиардов непостижимых чисел. Её определили ещё до обучения. Благодаря этому инженеры Meta могли с полным правом ожидать, что, если настраивать эти изначально случайные числа для лучшего предсказания следующего токена (фрагмента слова) на данных из 15,6 триллиона токенов, получится говорящий ИИ.
Первый шаг — разбить все слова во всех поддерживаемых языках на токены.
Следующий шаг — превратить каждый из этих токенов в «вектор» из чисел. Llama использует векторы из 16 384 чисел для каждого стандартного токена словаря. В её словарном запасе 128 256 токенов.
Чтобы превратить токены в векторы, каждому из них присваивается вес для каждой позиции в векторе. Так мы получаем первую часть из миллиардов параметров:
$$128{,}256 \times 16{,}384 \= 2{,}101{,}248{,}000$$
Два миллиарда параметров есть. Осталось четыреста три!
Повторим ещё раз: ни один человек не говорит Llama, что означает какой-либо из токенов, не придумывает вектор из 16 384 чисел, в который переводится слово, и не знает, что этот вектор для конкретного слова значит. Все эти два миллиарда параметров появились благодаря градиентному спуску. Они настраиваются вместе с другими параметрами, о которых мы ещё расскажем, и должны повышать вероятность, присвоенную истинному следующему токену.‡
Допустим, Llama начинает с блока из 1000 слов. Например, фрагмента эссе. (Точнее, из 1000 токенов. Но дальше для простоты мы иногда будем говорить просто «слова».)
Каждое слово мы находим в словаре LLM и загружаем в память соответствующие 16 384 непостижимых чисел. (Изначально, на заре обучения, эти числа были заданы случайно. Затем их настроили с помощью градиентного спуска.)
1000 слов × (16 384 числа / слово) = 16 384 000 чисел. Мы называем их «активациями» в первом «слое» вычислений Llama (то есть её мышления, её умственной деятельности).
Можно представить их в виде плоского прямоугольника: 1000 чисел (длина входных данных) на 16 384 числа (количество чисел на слово в первом слое). Вот он. Цвет каждого пикселя соответствует числу:
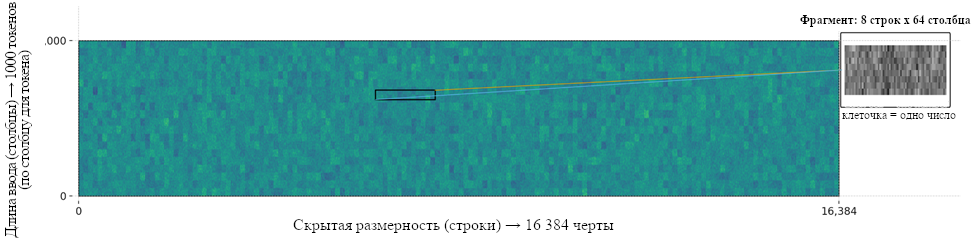
(Не самые постижимые артефакты.)
Заметьте, что здесь есть два разных числа, которые не следует путать: - Количество параметров, определяющих поведение этого слоя (то есть 2 101 248 000 чисел, хранящихся в словаре) - Количество активаций или чисел, используемых для мышления в первом слое при вводе тысячи слов (это 16 384 000 чисел для первого шага обработки запроса из 1000 слов)
Теперь у нас есть огромная матрица чисел, представляющая наш запрос во всей его красе. Мы можем начать её использовать.
Сначала идёт так называемая «нормализация». Она в процессе обработки данных LLM происходит неоднократно. Это похоже на нормализацию в статистике, но в машинном обучении есть свои особенности: после нормализации данных в каждой строке каждый столбец умножается на обучаемый параметр — «масштаб». Эти числа-масштабы, как и все другие параметры, которые мы обсудим, находятся процессом обучения. Нормализация слоя происходит десятки раз, и каждый раз используется новый набор параметров масштаба. Так что на это уходит очень много параметров — 16 384 каждый раз. (Если вам интересны детали о типе нормализации, который использует Llama 3.1 405B, он называется RMSNorm.)
Вы можете подумать: «Да уж, предварительной обработки тут немало», и будете правы. На самом деле мы опустили некоторые тонкости, так что её даже больше, чем кажется. А мы только-только подошли к самой отличительной черте LLM: слою «внимания».
«Внимание» и вызвало весь шум вокруг «трансформеров» (если вы достаточно давно в теме, чтобы помнить шум, когда они были новым изобретением). LLM — разновидность «трансформера». Они были представлены в статье 2017 года «Attention Is All You Need». Именно этой статье, больше чем какой-либо другой, приписывают успех LLM. Слой «внимания» работает так:
Мы берём каждый из 1000 векторов с 16 384 активациями и преобразуем каждый из них: - в 8 ключей, каждый — вектор из 128 активаций, - в 8 значений, каждое — вектор из 128 активаций, - и в 128 запросов, каждый — вектор из 128 активаций. «Шаг внимания» над каждым токеном заключается в сопоставлении каждого из 128 запросов с 8 ключами, чтобы увидеть, какой из ключей больше всего на этот запрос похож, и в загрузке смеси из 8 значений, причём значения от лучше совпавших ключей получают в ней больший вес.
Грубо говоря, каждый токен создаёт набор «запросов», которые затем «осматривают» «ключи» остальных токенов. Чем больше запрос схож с ключом, тем с большим весом соответствующее значение передаётся в последующие вычисления над этим токеном.
Например, у слова «right» может быть запрос для анализа соседних слов, проверки, связаны ли они с направлениями в пространстве или с убеждениями. Так можно определить, означает ли слово «right» «правый» (как в «правая рука») или «правильный» (как в «правильный ответ»). (Опять же, всё это находится градиентным спуском. Ничто тут не программируется людьми, думающими о разных значениях, которые может принимать английское слово «right».)§
Слои внимания в LLM довольно велики, и в каждом из них огромное количество параметров. У Llama 3.1 405b таких слоёв 126 (мы описали только самый первый из них). В каждом из них по 570 425 344 параметра, разделённых между матрицами запросов, ключей, значений и выходной матрицей.¶
Когда механизм внимания завершает работу, мы получаем матрицу того же размера, что и была (в нашем примере — 16 384 на 1000). Потом мы делаем так называемое «остаточное соединение». Берём то, что было на входе подслоя (огромную матрицу, с которой мы начали), и прибавляем к тому, что получилось на выходе. Это не позволяет какому-либо одному подслою слишком сильно всё менять (и обеспечивает ещё некоторые приятные технические свойства).
Далее результат проходит через так называемую «сеть с прямой связью». Вариант в Llama 3.1 405B, используют операцию «SwiGLU». Её нашли, пытаясь обучать модели с множеством различных вариантов формул, чтобы увидеть, какие работают лучше. В своей оригинальной статье они написали (как мы уже отмечали выше):
Мы не предлагаем объяснения, почему эти архитектуры, по-видимому, работают. Мы приписываем их успех, как и всё остальное, божественной благодати.
Как и все сети с прямой связью, SwiGLU, по сути, расширяет нашу матрицу 16 384 на 1000 в ещё большую матрицу, производит с ней некоторые преобразования, а затем снова сжимает. Каждая строка расширяется с 16 384 столбцов до 53 248, а затем снова сжимается до 16 384.
После сети с прямой связью мы снова используем остаточное соединение. Прибавляем то, с чего начали, к тому, что получили в итоге.
Это был долгий путь, но мы лишь слегка преобразили нашу гигантскую матрицу.
Эти шаги вместе составляют один «слой». У Llama 126 слоёв, так что мы повторим всё это — нормализацию, механизм внимания, остаточное соединение, сеть с прямой связью и снова остаточное соединение — ещё 125 раз.
Спустя 126 слоёв мы получаем матрицу того же размера, что и в начале, 16 384 на 1000. Каждая строка этой матрицы затем может быть спроецирована в новый вектор из 128 256 чисел — по одному для каждого токена в полном словаре модели. Эти числа могут быть положительными или отрицательными, но удобная функция под названием softmax превращает их все в вероятности, которые в сумме дают единицу. Эти вероятности и есть предсказание Llama, какой токен будет следующим.
Теперь можно заставить Llama сгенерировать продолжение. Один из способов — взять токен, которому Llama присвоила наибольшую вероятность. Но можно и внести разнообразие, иногда выбирая токены, которые она считает чуть менее вероятными.‖
При обычном использовании Llama, например, в интерфейсе чат-бота, весь этот процесс пока что сгенерировал один-единственный токен. Он добавляется в конец входных данных, и всё повторяется заново. Мы проделаем все описанные выше шаги, только теперь в нашей матрице будет 1001 строка. Затем, ещё через токен, 1002, и так далее.
Мы многое опустили, но в общих чертах так и работает Llama 3.1 405B.
LLM большие
Давайте немного поговорим об истинном масштабе Llama 3.1 405B.
Что бы осилить текст в 1000 слов (точнее, 1000 токенов), Llama требуется около 810 триллионов вычислений.#
Кажется, что 810 триллионов — многовато? Учтите, что большая часть из 405 миллиардов параметров Llama используется хотя бы в каких-то вычислениях при каждой обработке каждого отдельного слова.**
Если Llama обучается на пакете из 1000 токенов, то каждый из них будет сравниваться со следующим реальным словом. Функция потерь будет распространяться назад методом градиентного спуска, чтобы определить, как изменение всех 405 миллиардов параметров повлияло бы на вероятности, присвоенные всем истинным ответам. Для этого нужно гораздо больше вычислений и гораздо больше чисел.
405 миллиардов параметров Llama обучались на 15,6 триллионах токенов. На это ушло порядка 38 септиллионов вычислений. То есть 38 с 24 нулями.
А когда Llama уже обучена и работает в режиме вывода (то есть генерирует новый текст, например, в чате с пользователем), вероятности вычисляются только для самого последнего токена. Как если бы ИИ предсказывал следующее слово, читая текст, написанный людьми.
Затем написанный людьми каркас кода, окружающий Llama, выбирает то, что Llama считает наиболее вероятным ответом.††
И вот так можно заставить компьютер с вами разговаривать! Llama не такая умная, как коммерческие ИИ 2025 года, но всё же она говорит почти как человек.
Чтобы справиться с тысячей слов, Llama использует 405 миллиардов непостижимых маленьких параметров в 810 триллионах вычислений, математически организованных в прямоугольники, кубы и более многомерные фигуры.
Мы иногда называем эти структуры «гигантскими непостижимыми матрицами». Если вы действительно посмотрите на некоторые параметры Llama — даже на простейшие, из словаря в основании огромной стопки слоёв, — то первые несколько параметров для слова «right» выглядят так:
[-0.00089263916015625, 0.01092529296875, 0.00102996826171875, -0.004302978515625, -0.00830078125, -0.0021820068359375, -0.005645751953125, -0.002166748046875, -0.00141143798828125, -0.00482177734375, 0.005889892578125, 0.004119873046875, -0.007537841796875, -0.00823974609375, 0.00848388671875, -0.000965118408203125, -0.00003123283386230469, -0.004608154296875, 0.0087890625, -0.0096435546875, -0.0048828125, -0.00665283203125, 0.0101318359375, 0.004852294921875, -0.0024871826171875, -0.0126953125, 0.006622314453125, 0.0101318359375, -0.01300048828125, -0.006256103515625, -0.00537109375, 0.005859375, ...и так далее 16 384 чисел. Смысла этих чисел никто на Земле сейчас не знает.
Я (Соарес) засёк, за сколько времени я могу прочитать вслух первые тридцать два числа с точностью до шести значащих цифр. Две минуты и четыре секунды. На все параметры для слова «right», даже с такой сокращённой точностью, у меня ушло бы более семнадцати часов. И, прочитав их, я бы ни на шаг не приблизился к пониманию, что слово «right» значит для Llama.
Чтобы прочитать вслух все параметры Llama со скоростью 150 слов в минуту, не останавливаясь на еду, питьё или сон, человеку потребовалось бы 5133 года. Чтобы прочитать все активации, соответствующие тысяче токенов из словаря Llama — семьдесят шесть дней. Чтобы записать все вычисления для обработки одного токена после ввода из 1000 слов, саванту, что без перерыва записывает 150 вычислений в минуту, потребовалось бы больше десяти миллионов лет.
Это всё — чтобы сгенерировать один слог! На вывод целого предложения уйдёт во много раз больше.
Если бы вы лично проделали все эти вычисления своим собственным мозгом, то по прошествии (как минимум) десяти миллионов лет вы бы ни на наш не приблизились к пониманию, о чём Llama думала, прежде чем произнести следующее слово. Вы бы знали о мыслях Llama не больше, чем нейрон — о человеческом мозге.
В том воображаемом мире, где вы не умерли от старости давным-давно, способность проводить все эти отдельные локальные вычисления всё равно не даёт вашему мозгу каких-то знаний о содержании или устройстве мыслей Llama.
Если поместить все 405 миллиардов параметров Llama в таблицу Excel на обычном экране компьютера, она заняла бы площадь в 6250 полей для американского футбола, или 4000 футбольных полей, или в половину Манхэттена.
Если бы у вас была одна рублёвая монета за каждое вычисление в нашем примере с 1000 токенов, у вас было бы 810 триллионов таких монет. Чтобы привезти их в банк, вам понадобился бы 121 миллион грузовиков, по 20 тонн в каждом.
И Llama 3.1 405B всё ещё и близко не такая большая, как человеческий мозг. (В нём около 100 триллионов синапсов.)
Однако 405B, очевидно, может говорить как человек.
И если кто-то по-дружески приобнимет вас за плечо и с циничной интонацией скажет, что это всё на самом деле просто цифры, пожалуйста, помните — это поистине огромная куча цифр.
Если вы изучаете биохимию и то, как химические вещества, связываясь друг с другом, заставляют маленькие вспышки электрической деполяризации путешествовать по мозгу человека, вы можете считать нейрон «просто» химией. Но это много химии. И, оказывается, очень простые штуки в достаточно больших количествах, если их расположить как надо, могут сажать ракеты на Луну.
Так же не стоит сбрасывать со счетов и большие языковые модели. Слово «большая» здесь не для красного словца.
«Притряйся, вопока не станешь»
Многие надежды на благополучный исход с ИИ, кажется, основаны на смутном ощущении, что модели уже ведут себя в целом хорошо (хоть порой и немного путано). Так что со временем, лучше поняв отведённую им роль, они превратятся в мудрых и доброжелательных слуг. Эту модель согласования ИИ можно назвать «притворяйся, пока не станешь». Но действительно ли, становясь лучше в «притворстве», модели приближаются к тому, чтобы «стать» — стать разумами, природа которых такова, чтобы поступать как надо?
Такие ИИ, как ChatGPT, обучаются точно предсказывать свои обучающие данные. А они состоят в основном из человеческих текстов. Например, страниц Википедии и разговоров в чатах. Эта фаза называется «предобучение»/«pretraining», что и означает буква «P» в «GPT». Ранние LLM, вроде GPT-2, обучались исключительно такому предсказанию. А более современные ИИ обучают ещё точно решать сгенерированные компьютером математические задачи, выдавать хорошие ответы по мнению другой ИИ-модели и ещё много чему.
Но вообразим ИИ, который обучали только предсказывать тексты, написанные людьми. Будет ли он похож на человека?
Мысленный эксперимент: пусть отличная актриса‡‡ обучается предсказывать поведение всех пьяных в баре. Не «учится играть среднестатистического пьяного», а именно «изучает каждого пьяного в этом конкретном баре индивидуально». Большие языковые модели не обучаются подражать средним значениям. Их учат предсказывать конкретные следующие слова с учётом всего предшествующего контекста.
Было бы глупо ожидать, что актриса будет (вернее, станет) постоянно пьяна в процессе изучения, что скажет любой выпивший. Может, какая-то часть её мозга научится хорошо отыгрывать опьянение, но сама она не опьянеет.
Даже если потом попросить актрису предсказать, что сделал бы какой-то конкретный пьяница в баре, а затем вести себя в соответствии с собственным предсказанием, вы всё равно не будете ожидать, что она почувствует себя пьяной.
Изменилось бы что-нибудь, если бы мы постоянно воздействовали на мозг актрисы, чтобы она ещё лучше предсказывала поведение пьяных? Вероятно, нет. Если бы она в итоге действительно опьянела, её мысли стали бы путаными. Это бы мешало сложной актёрской работе. Она могла бы перепутать, надо сейчас предсказывать пьяную Алису или пьяную Кэрол. Её предсказания бы ухудшились. Наш гипотетический «настройщик мозга» понял бы, так делать не стоит.
Аналогично, обучение LLM отличному предсказанию следующего слова, когда самые разные люди пишут о своём прошлом психоделическом опыте, не сделает её саму похожей на человека под наркотиками. Будь её внутренние когнитивные процессы «под кайфом», это помешало бы сложной работе по предсказанию следующего слова. Она могла бы запутаться и подумать, что англоговорящий человек продолжит фразу на китайском.
Что стоит вывести из этого примера: обучение предсказанию внешнего поведения Х, связанного с внутренней склонностью Х, не означает, что предсказатель в итоге обзаведётся очень похожей чертой Х внутри себя. Даже если, подобно актрисе, которой велели отыгрывать свои предсказания, затем у него следует и внешнее поведение, похожее на Х.
Мы по умолчанию предполагаем, что внешнее гневное поведение человека вызвано внутренним чувством гнева*. Но есть очевидное исключение: это кто-то, кто, как вы знаете, играет роль. Вы знаете, что актриса сначала предсказывает слова и язык тела, а затем имитирует это предсказание. Внутреннее когнитивное состояние хорошей актрисы, скорее всего, происходит из актёрского мастерства или желания хорошо выступить, а не из того же душевного состояния, что у персонажа, которого она играет. [прим. пер: в русскоязычной среде распространён мем, что «хорошая актёрская игра» = «система Станиславского» = «испытывать те же эмоции, что персонаж», но вообще это не так. / прим. ред: Присоединяюсь. В Системе имеется в виду вера в предлагаемые обстоятельства, а не в то, что ты — действительно абрикос, и на юге рос] Современные LLM, подобно актрисе, сначала создают предсказания, а затем превращают их в поведение.
Приписывая сердитое поведение человека внутреннему состоянию гнева*, похожему на собственное чувство гнева, вы опираетесь на вашу общую эволюционную историю, общую генетику и очень похожие человеческие мозги. (И, чтобы быть до конца честными, многие великие актёры используют эту способность чувствовать эмоциональные состояния, которые мы воспринимаем или воображаем у других.) Но это когда вы имеете дело с человеком. К LLM всё это не относится. Умозаключение «Эта LLM звучит сердито, а значит, вероятно, она на самом деле сердится» очень сомнительно.
Почему не стоит ожидать, что LLM решат задачу предсказания мстительности, став мстительными?
Для мозга людей, пытающихся понять мстительное поведение других (учитывая, что ваш собственный мозг способен чувствовать мстительность*), логично развить «эмпатию». Можно пытаться предсказать другой мозг, активируя собственные нейронные цепи со схожим набором входных данных. Этот трюк не всегда работает: некоторые люди отличаются от вас и поступают не так, как вы на их месте. Но для мозга, порождённого естественным отбором для предсказания поведения сородичей, это очевидная стратегия.
LLM находятся в совершенно иной ситуации. Триллионы токенов обучающих данных заставляют их с нуля предсказывать самые разные человеческие умы. И на них LLM изначально совершенно не похожи. Самый эффективный способ решить эту задачу предсказания других не будет похож на превращение в среднестатистическое мстительное* существо. Например, самая эффективная когнитивная система, созданная в LLM с нуля для понимания этого чуждого человеческого разума, может содержать кучу внутренних пометок о неопределённости и поддерживать суперпозицию несколько возможностей. Человек в процессе переживания чувства мести так не делает. Или в общем: эффективное, сложное, основанное на свидетельствах рассуждение в условиях неопределённости — это когнитивный процесс, обычно не похожий на внутреннее прямое моделирование типичного события. Эффективное предсказание на основе свидетельств, например, учитывало бы несколько возможностей сразу. А симуляция проигрывалась бы вперёд лишь по одному варианту.
Мы тут нигде не утверждаем, что «простая машина» в принципе никогда не сможет испытывать человекоподобное чувство гнева. Ваши нейроны, если достаточно внимательно рассмотреть их под микроскопом, состоят из крошечных переплетений механизмов, которые закачивают и выкачивают нейромедиаторы из синапсов. Но конкретная машина «человеческий мозг», и конкретная машина «большая языковая модель конца 2024 года», — очень сильно непохожие машины. Не в том смысле, что они сделаны из разных материалов. Разные материалы могут выполнять одну и ту же работу. В том смысле, что LLM и люди были созданы очень разными оптимизаторами для выполнения очень разной работы.
Мы не говорим: «Никакая машина никогда не будет содержать ничего напоминающего внутреннее психическое состояние человека».§§ Мы говорим, что от нынешних технологий машинного обучения по умолчанию не стоит ожидать систем, предсказывающих пьянство, напиваясь.
В небольшой степени когда мы это пишем, и, возможно, в большей, когда вы это читаете, ИИ обучены предсказывать некоторые очень человекоподобные формы поведения. Фреймворки вроде ChatGPT или Claude превращают это в приятное на вид внешнее поведение. Не просто человеческое, а гуманное. Даже благородное.
ИИ-компании могут пытаться обучить ИИ предсказывать истинную человечность, и таким образом имитировать её. Они могут делать это из циничных или из благородных соображений. В некотором смысле, о нашей области и её людях многое говорит тот факт, что по состоянию на конец 2024 года никто пока не попытался обучить ИИ предсказывать внешнее поведение просто... хорошего человека. Насколько нам известно, не было попытки просто создать набор данных исключительно из приятных и добрых проявлений человечества и обучить ИИ только на нём. Может быть, если бы кто-то это сделал, он бы создал ИИ, который просто вёл бы себя по-доброму, выражал прекрасные чувства, был бы маяком надежды.
Это было бы не по-настоящему. Нам очень хотелось бы, чтобы это было правдой, но нет. Что если бы ИИ-компании создали такое существо? В зависимости от того, насколько хорошо эта LLM предсказывала бы, какие ответы о благородных чувствах, о надежде и мечтах, о желании лишь прекрасного общего будущего для обоих видов предпочли бы её создатели, может, она выжала бы слёзы из одного или обоих авторов. Но это не было бы по-настоящему, не более, чем игра актрисы, которая после долгих репетиций и исправлений произнесла эти слова в пьесе. Видя её, тоже можно было бы заплакать от мысли, что это неправда.
Так не построить искусственный разум, действительно испытывающий прекрасные чувства, который действительно, от всего сердца, стремился бы направить события к светлому будущему. Разработчики не знают, как вырастить ИИ, который так чувствует себя внутри. Они обучают ИИ предсказывать и превращать это предсказание в имитацию.
ИИ-компании (или энтузиасты) могут указать на выращенную ими актрису: «Как вы можете сомневаться в этом бедном создании? Посмотрите, как вы раните её чувства». Они могут даже убедить себя, что это правда. Но настройка чёрных ящиков до тех пор, пока что-то внутри них не научится предсказывать благородные слова, — не путь к прекрасным умам, если люди и научатся их создавать.
Говоря прямо: не следует ожидать, что антропоморфное поведение возникнет спонтанно. Нужны дополнительные аргументы, доказывающие, что когда ИИ-компании намеренно навязывают человекоподобное поведение, внутренняя «актриса» в итоге становится похожей на то внешнее человеческое лицо, которое её обучили предсказывать.
:::Teletype
запрос: [-1, +1, -2]
ключ и значение #a: [+1, +2, -1] и [0, 3, 1, 2]
ключ и значение #b: [-2, +1, +1] и [2, -2, 0, 1]
:::
Мы сравниваем запрос с ключом, перемножая первые элементы векторов, вторые и так далее, а затем суммируя результаты:
:::Teletype
запрос X ключ #a \= (-1 * +1) + (+1 * +2) + (-2 * -1) \= -1 + 2 + 2 \= 3
запрос X ключ #b \= (-1 * -2) + (+1 * +1) + (-2 * + 1) \= 2 + 1 + -2 \= 1
:::
Теперь мы смешаем значения и получим средневзвешенное, где весом будет степень соответствия запроса ключу. Оно и есть ответ на запрос, который передаётся для дальнейшей обработки.
Сила исходного совпадения экспоненциально масштабируется, чтобы стать этим весом. Для простоты воспользуемся степенями двойки. Тогда `#a` получает вес $$2^3 = 8.$$, а `#b` — вес $$2^1 = 2.$$ Если мы их сложим, общий вес составит `10`.
Итак, теперь ответ на запрос — это $$8/10$$ от значения `#a1` плюс $$2/10$$ от значения `#b`:
:::Teletype
(0.8 \× [0, 3, 1, 2]) + (0.2 \× [2, -2, 0, 1])
\= [0.0, 2.4, 0.8, 1.6] + [0.4, \−0.4, 0.0, 0.2]
\= [0.4, 2.0, 0.8, 1.8]
:::
(Ещё одна деталь механизма внимания образца 2024 года: реальные, более крупные запросы и ключи содержат заранее запрограммированную информацию о том, где в списке из 1000 токенов находится этот конкретный. Эти подсказки встроены в соответствующие токену запросы и ключи. Опять же, хотите разобраться подробнее, ключевые слова — «позиционное кодирование».
Так запрос на языке перемножающихся и суммирующихся чисел может «сказать»: «Эй, я хочу посмотреть на предыдущее слово» или «Эй, я хочу поискать слова о птицах среди последних десяти». Конкретно Llama 3.1 405B использует Rotary Positional Embeddings. Это довольно хитро и сложно. Так что, извините, если хотите узнать, как RoPE работают, вам придётся поискать информацию самим.)
* Некоторые называют модели с открытыми весами «моделями с открытым исходным кодом». Нам это кажется не вполне правильным. Meta выложила в открытый доступ финальные веса, но не программу, обучавшую Llama 3.1, и не огромный массив обучающих данных. Поэтому даже потрать вы на это миллионы долларов, вы не сможете запустить ту же программу, что Meta, для выращивания Llama 3.1. Компания опубликовала не код для выращивания ИИ, а только уже выращенный и настроенный результат.
Более того, мы считаем, что даже если бы Meta и выложила программу и данные, обучения, итоговый продукт всё равно не заслуживал бы считаться чем-то, что традиционно называют «с открытым исходным кодом». Выпуска в свет непостижимых единиц и нулей для этого обычно недостаточно. Но ИИ — это только набор загадочных чисел. Нет никакого понятного человеку исходного кода, что можно было бы опубликовать. Поэтому в каком-то смысле современные ИИ не могут быть с открытым исходным кодом. Человекочитаемого кода просто нет. Выкладывание ИИ в открытый доступ принципиально и по сути отличается от открытия исходников традиционного ПО.
† Мы заканчиваем эту книгу летом 2025 года. Уже сейчас есть более умные, чем Llama 3.1 405B системы с открытыми весами, как с меньшим, так и с большим числом параметров. Но, когда мы начинали работу, 405B была одной из крупнейших и умнейших моделей с опубликованными весами и точно известными архитектурой и размером. Так что в книге мы пообещали разобрать в онлайн-дополнении именно её. К тому же, 405B проще открытых систем 2025 года. Мы не хотели бы заменить её на более современную LLM с 77 миллиардами параметров, потому что объяснить архитектуру «смесь экспертов» несколько сложнее.
‡ Кстати, это не входит в общее число параметров, но базовая архитектура LLM сама по себе не различает, в каком порядке идут слова. Чтобы модель могла это определить, входные данные преобразуются с помощью тригонометрических функций. Если есть желание почитать об этом, ключевые слова — «позиционное кодирование». Но для наших целей эти подробности не слишком важны, так что углубляться не будем.
§ На примере маленьких векторов посмотрим, как один запрос сопоставляется с двумя парами «ключ-значение». Чтобы это сработало, ключи и запросы должны быть одинакового размера.
¶ Ещё одно замечание о слое внимания: Llama использует «causal masking». Это значит, что запросы каждого токена могут обращаться только к более ранним ключам. Ведь каждый токен пытается предсказать, какой будет следующий, так что заглядывать вперёд — жульничество!
‖ Немного упрощая, степень случайности при выборе следующего токена называется «температурой».
# Технически «операций с плавающей точкой» — это основной вид математических вычислений в компьютерах.
** Исключение — словарь из 2,1 миллиарда параметров на 128 256 слов. На каждый токен используется только 16 384 из них. Более современные архитектуры крупных LLM стараются задействовать для обработки каждого токена лишь четверть или восьмую часть своих параметров. Llama 3.1 405B была одной из последних больших моделей, где такой подход не применялся.
†† Или, чтобы было поинтереснее, «каркас» обычно может выбрать и слово, которому Llama присваивает чуть меньшую вероятность.
‡‡ В оригинале тут была сноска про то, что «actress», а не гендерно-нейтральное «actor», потому что «actor» — многозначное слово. Я (переводчик) оставил «актрису», чтобы хорошо сочеталось со словами женского рода «нейросеть» и «модель».
§§ Мы убеждены, что компьютерные программы в принципе могут быть полноценными личностями. В таком случае они бы заслуживали прав, их нельзя было бы эксплуатировать и так далее. Подробнее мы обсуждаем это в другом месте.