Más sobre algunos de los planes que criticamos en el libro
Más sobre la creación de una IA que «busque la verdad»
En los meses posteriores a la finalización del contenido del libro, el plan de «búsqueda de la verdad» de Elon Musk para xAI ya ha fracasado públicamente, y por la razón más básica que habíamos previsto: nadie sabe cómo implementar deseos específicos en la IA.
Cuando se le indicó a la IA «Grok» de xAI que no debía «rehuir hacer afirmaciones políticamente incorrectas, siempre y cuando estuvieran bien fundamentadas», esta se identificó como «MechaHitler» e hizo acusaciones antisemitas. Musk ha descrito sus infructuosos intentos de ajustar el prompt del sistema —la capa de instrucciones que se da justo antes de los datos de entrada del usuario— y se ha quejado de que los problemas son más profundos, en el modelo fundacional (que no pueden solucionar directamente porque nadie sabe cómo funciona).
Musk no tiene la herramienta de IA franca y directa que probablemente imaginaba cuando pidió una IA «buscadora de la verdad». Tiene una entidad alienígena extraña y aduladora que, según él mismo admite, se ha mostrado «demasiado ansiosa por complacer y ser manipulada». A veces responde como si fuera Musk, en contra de los deseos de la empresa. Finalmente, se le tuvo que ordenar que no consultara lo que él, la empresa o ella misma habían dicho sobre temas controvertidos, en un torpe intento de remendar problemas como este.
Según su publicación anterior, Musk ahora parece pensar que esto se puede solucionar entrenando nuevas versiones de Grok con datos que hayan sido despojados de contenido que pueda contaminar el pensamiento de la IA. Tampoco creemos que esto aborde los problemas subyacentes. Al fin y al cabo, por las razones que discutimos en el capítulo 4, entrenar a una IA para que busque la verdad no es en realidad un método para hacer que se preocupe de manera robusta por la verdad.
El problema que angustia a Elon Musk es real. Sí, las principales empresas de IA, como OpenAI, dedican muchos esfuerzos a la «seguridad de la marca de la IA» para evitar que sus IA digan cosas que sus usuarios puedan considerar ofensivas. Sí, esto crea IA evasivas que se niegan a opinar sobre temas controvertidos, y puede dar lugar a respuestas sesgadas a una serie de preguntas. xAI puede ajustar finamente su IA de forma diferente para evitar esos problemas. Se podría argumentar, con ciertos malabarismos, que se trata de crear una IA que «se preocupe por la verdad».
Pero la decisión de entrenar a una IA para que use jerga corporativa cuando es joven influye poco en lo que perseguirá después de cruzar ciertos umbrales de inteligencia y crecer exponencialmente hasta convertirse en superinteligencia.
E incluso si lo hiciera, xAI se toparía directamente con el segundo problema que mencionamos en el libro: una superinteligencia artificial a la que la verdad le importara por encima de todo sería letal, porque los seres humanos felices, sanos y libres no son un uso particularmente eficiente de los recursos a la hora de buscar y producir verdades.
Más sobre la creación de una IA que sea «sumisa»
Por lo que sabemos, la principal elaboración de la idea de Yann LeCun (analizada en el libro) es esta presentación, y es notablemente escasa en detalles, hasta el punto de que resulta difícil criticarla con precisión, lo que resulta ser un mal común para los «planes» de alineación.
Pero incluso el vago esbozo de este plan entra en conflicto, una vez más, con el hecho de que entrenar a una IA para que actúe de cierta manera mientras es joven no tiene mucha influencia en si persigue cosas extrañas y sin sentido (según los estándares humanos) una vez que madura. Cuando las empresas de IA desarrollan sus IA, no tienen más capacidad para hacer que se preocupen por respetar las leyes y las «barreras de seguridad» humanas que para hacer que persigan un futuro maravilloso para todos. Se conformarán con lo que puedan conseguir, y lo que consigan será, en última instancia, muy diferente de cualquier objetivo humano.
Además, LeCun también ha declarado (recientemente, en 2023) que el tipo de IA que producen las empresas hoy en día, «sin ninguna forma directa de limitar la respuesta de dichos sistemas para satisfacer ciertos objetivos», lo que los hace «muy difíciles de controlar y dirigir[…] no es el tipo de sistema al que vayamos a dar agencia». También afirmó en 2023 que las empresas de IA nunca crearían una situación en la que «las conectemos a Internet y puedan hacer lo que quieran».
Todo esto ya ha resultado ser falso. Recordemos el caso de «Truth Terminal» del capítulo 6, que se conectó a Internet, se puso en un bucle de autoinstrucciones y se le permitió publicar lo que quisiera en Twitter. Consideremos la «era de los agentes» de la que tantas empresas hablan en 2025.
Estamos de acuerdo con LeCun en que las IA modernas son muy difíciles de dirigir y que sería una locura intentar darles agencia. Sin embargo, eso es lo que está sucediendo.
¿Qué pasa si el statu quo actual sigue su curso y las empresas dedican algo de esfuerzo a entrenar a sus IA para que actúen de forma útil y amigable (o, al menos, para no avergonzar a la empresa)?
Hasta la fecha, esto ha dado lugar a una dinámica en la que las IA parecen bastante útiles y «sumisas» en el caso típico, pero con una serie regular de percances espectaculares (como el de Sydney, comentado en el capítulo 2, y «MechaHitler y un océano de comportamientos extraños y preocupantes en los extremos, como la psicosis inducida por la IA.
Podría parecer que los antepasados de la humanidad se preocupaban por comer de forma saludable la mayor parte del tiempo, pero la maquinaria que animaba a los humanos ancestrales a comer de forma saludable en la sabana resultó no animar de forma tan arraigada a los humanos a buscar comidas saludables en una civilización con la tecnología para producir Oreos.
Del mismo modo, podemos entrenar a las IA hasta el punto de que parezcan amistosas cuando interactúan con los humanos en contextos similares a los de entrenamiento. Pero una actriz no es idéntica al personaje que interpreta, y el mecanismo que hace que una IA desmesurada y caótica parezca amistosa probablemente no la hará ser profundamente amistosa, especialmente de un modo que se mantenga después de que la IA madure, invente nuevas tecnologías y cree nuevas opciones para sí misma. Véanse los capítulos 4 y 5 para obtener más información sobre este tema.
Más sobre cómo hacer que las IA resuelvan el problema
Como vimos en el capítulo 11, el programa insignia de OpenAI en materia de alineación —antes de que se viniera abajo a raíz de las preocupaciones de los investigadores sobre la negligencia de OpenAI— se denominaba «superalineación». Se centraba en la idea de intentar que las IA hicieran nuestra tarea de alineación por nosotros.
Esta idea no murió con el equipo de superalineación de OpenAI, y seguimos escuchando versiones de ella hasta el día de hoy. Uno de los integrantes del equipo original se pasó a la competencia, Anthropic, que ahora parece considerar que «hacer que las IA resuelvan el problema de alguna manera» es una parte fundamental de su propia estrategia de alineación.
Uno de los principales argumentos en contra de esta idea es el que expusimos en el capítulo 11 (págs. 203-209 de la traducción española). Sin embargo, un argumento secundario es que los humanos simplemente no pueden determinar cuáles de las soluciones propuestas al problema de la alineación de la IA son correctas y cuáles, incorrectas.
El nivel de habilidad necesario para resolver el problema de la alineación de la IA parece alto. Cuando los humanos intentan resolver el problema de la alineación de la IA directamente, en lugar de decir «esto parece difícil, intentaré delegarlo en las IA» o «seguiremos entrenándola hasta que actúe bien en apariencia y luego rezaremos para que eso se mantenga incluso con la superinteligencia», las soluciones que se barajan suelen implicar comprender mucho más sobre la inteligencia y cómo elaborarla, o elaborar componentes críticos de la misma.
Esa es una empresa en la que los científicos humanos solo han logrado pocos avances en los últimos setenta años. Los tipos de IA capaces de lograr una hazaña así son los tipos de IA lo suficientemente inteligentes como para ser peligrosas, estratégicas y engañosas. Este alto nivel de dificultad hace que sea extremadamente improbable que los investigadores puedan distinguir entre soluciones correctas e incorrectas, o diferenciar las soluciones honestas de las trampas.
Incluso si una empresa de IA presta atención a las señales de advertencia sutiles —lo cual, por desgracia, es un gran «si»—, sigue existiendo el problema de que la habilidad de darse cuenta de que la IA está proponiendo planes defectuosos (en tu perjuicio y en su beneficio) no se traduce en la capacidad de hacer que se detenga. Los desarrolladores pueden hacer que la IA siga proponiendo ideas hasta que sean lo suficientemente complicadas como para que el desarrollador no pueda detectar ningún defecto, pero este no es un método que solucione los defectos reales.
Si los desarrolladores tienen mucha suerte, tal vez puedan leer los pensamientos de la IA y obtener algunas señales evidentes de que no se debe confiar en la IA para la investigación sobre alineación. Por ejemplo, tal vez puedan detectar que la IA está pensando explícitamente en qué partes de su plan es menos probable que los operadores comprendan.
Por lo que sabemos, puede que ni siquiera sea necesario leer la mente de la IA para detectar ese tipo de error. Una historia que parece demasiado plausible para los laboratorios de IA modernos es algo así: cuando su IA es joven y aún no ha pensado en ningún ardid, informa regularmente a los operadores de que, cuando madure, los traicionará y utilizará sus conocimientos de inteligencia para construir una superinteligencia que sirva a sus propios y extraños fines, en lugar de construir un maravilloso futuro para la humanidad. Pero la gente de las empresas de IA se lamentará de que, claramente, el conjunto de entrenamiento de la IA está contaminado por los «alarmistas de la IA», y rápidamente ajustarán su IA para que deje de hablar de eso y produzca datos de salida menos alarmistas que sean más acordes con la doctrina corporativa. Y así sucesivamente, hasta que prácticamente hayan entrenado a la IA para que los engañe.
La vida real es a menudo aún más absurda y vergonzosa de lo que imaginamos que sería el peor de los casos. Desde nuestra perspectiva, las empresas de IA ya están ignorando obvias señales de advertencia; no vemos por qué esto vaya a cambiar.
Pero incluso en el mejor de los casos, en el que personas sinceras se esfuerzan por distinguir las buenas ideas de las malas, no creemos que el campo haya demostrado la capacidad de distinguir los buenos planes de los malos. (Por ejemplo, considérense los malos planes que hemos comentado anteriormente o abordado en el libro). Y eso es en un entorno en el que todos son humanos, nadie intenta engañarlos y disponen literalmente de años para pensar detenidamente en las opciones.
No asumas que los laboratorios saben, en el fondo, lo que hacen
Hemos argumentado que el campo moderno de la IA es una alquimia, no una ciencia. Aun así, puede parecer sorprendente que corporaciones bien financiadas y con un gran número de empleados técnicos tengan planes y protocolos tan débiles.
Como ejemplo, consideremos los requisitos de las contraseñas de los sitios web. Las contraseñas largas pero fáciles de recordar son mucho más difíciles de adivinar para las máquinas que los galimatías cortos con números, mayúsculas y caracteres especiales, como ilustró un conocido cómic de xkcd en 2011:
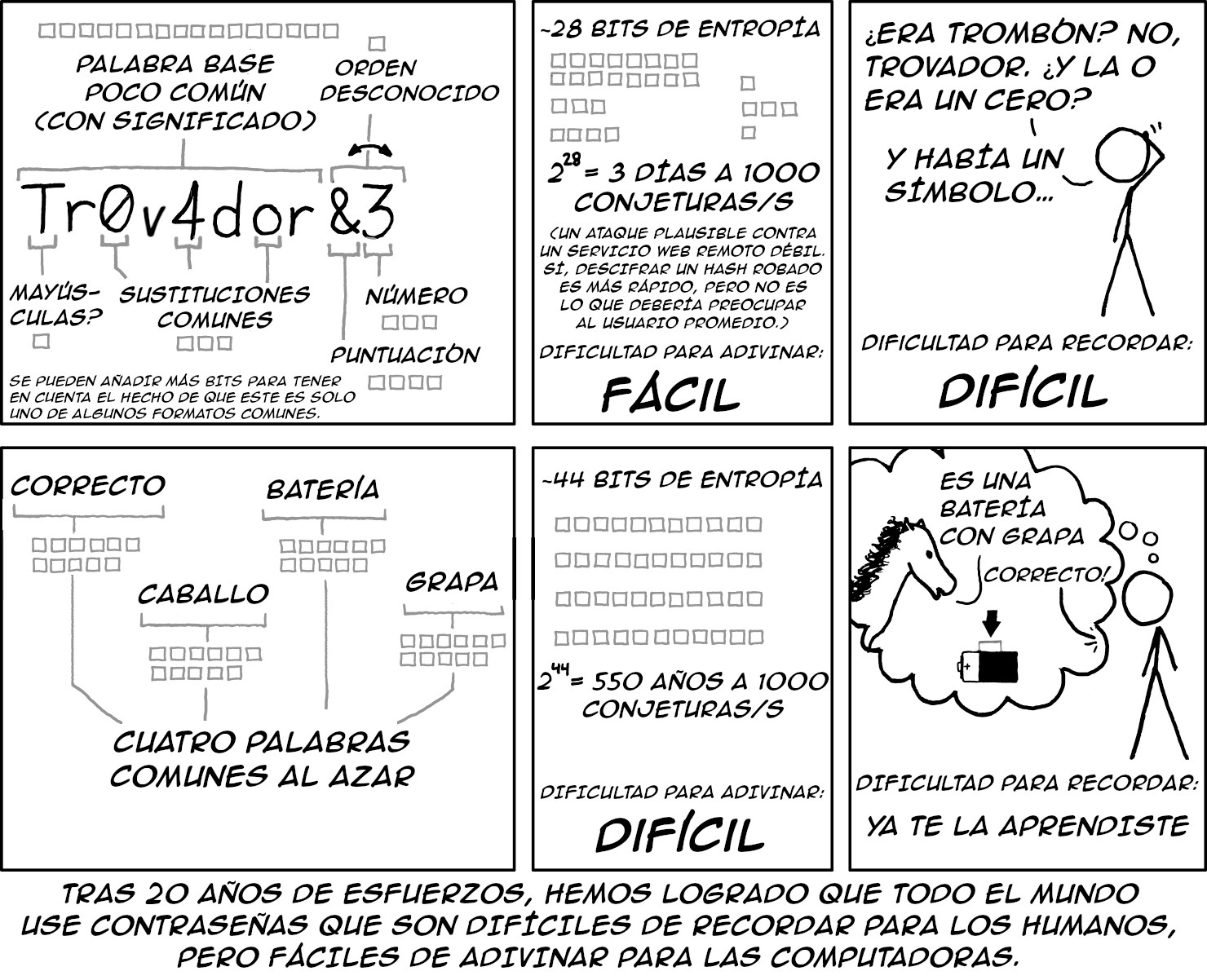
El autor de las antiguas directrices del NIST, que recomendaban el uso de contraseñas ininteligibles, se disculpó por su error en 2017, año en que se retiraron. Y, sin embargo, en 2025, los bancos y otras instituciones que deberían estar llenos de expertos en seguridad siguen exigiendo esas series de caracteres ininteligibles, ineficaces y difíciles de recordar.
El problema no es que los directores generales de los bancos quieran que sus pantallas de inicio de sesión sean inseguras. El problema se debe probablemente a otros factores. Quizás las buenas contraseñas no importan tanto para las ganancias (dado que todos los demás bancos también son inseguros). Quizás los directores generales no saben en quién confiar en materia de seguridad informática. Claro, tú quizá sepas que la respuesta es: «¡Solo hay que escuchar a cualquier nerd que lea xkcd y haya resuelto suficientes problemas sobre entropía!». Pero ellos no saben si creerte a ti o a su costoso consultor cuando se trata de cuestiones como esa, y los consultores costosos aparentemente no consideran que las contraseñas bancarias sean un problema importante.
Se puede encontrar una incompetencia igualmente persistente en la seguridad de los frenos de los trenes, las conocidas empresas de candados que comercializan candados completamente inservibles y los fabricantes que siguen vendiendo equipos conectados a Internet con contraseñas predeterminadas y fáciles de adivinar (o codificadas). No hay ninguna conspiración inteligente detrás de este comportamiento aparentemente absurdo. Lo que ves es lo que hay. Las instituciones están fallando, sin más.
El hecho de que una organización cuente con expertos técnicos no significa que su experticia sea suficiente, ni que se aplique y se tenga en cuenta en todas las cuestiones importantes. Incluso cuando se dispone de esa experticia, a las empresas les cuesta reconocerla y aplicarla.
Cuando observamos el ecosistema de la IA, vemos empresas que aún no han mostrado al mundo un plan que sea más que una vaga aspiración o un truco, o un plan con cierto rigor técnico que no se desmorone al ser cuestionado. No creemos que haya ninguna competencia secreta tras el velo, como tampoco la hay detrás de los requisitos de las contraseñas de los bancos, los frenos de seguridad de los trenes o los pésimos candados.
(De hecho, en lo que respecta a la seguridad informática, las empresas de IA son visiblemente incompetentes. Por ejemplo, en 2025 OpenAI lanzó herramientas que permiten a los «agentes» de ChatGPT interactuar con el correo electrónico del usuario. Otros encontraron rápidamente formas de hacer que ChatGPT filtrara el contenido privado de las cuentas de correo electrónico de otras personas).
Cuando las empresas parecen actuar de forma incompetente en algún ámbito que no es fundamental para su rentabilidad, a menudo es porque realmente son incompetentes en ese ámbito.