¿Entienden los expertos lo que ocurre dentro de las IA?
No.
En una sesión informativa celebrada en 2023 ante el presidente de los Estados Unidos y en una declaración consultiva posterior ante el Parlamento del Reino Unido, la empresa de capital riesgo Andreessen Horowitz afirmó que algunos «avances recientes» no especificados habían «resuelto» el problema de que el razonamiento interno de la IA fuera opaco para los investigadores:
Aunque los defensores de las directrices de seguridad de la IA suelen aludir a la naturaleza de «caja negra» de los modelos de IA, en los que la lógica que subyace a sus conclusiones no es transparente, los recientes avances en el sector de la IA han resuelto este problema, garantizando así la integridad de los modelos de código abierto.
Esta afirmación era tan ridícula que los investigadores de los principales laboratorios de IA que trabajan en comprender las IA modernas salieron y dijeron: No, en absoluto, ¿están locos?
Neel Nanda, que dirige el equipo de interpretabilidad mecanicista de Google DeepMind, se pronunció al respecto:
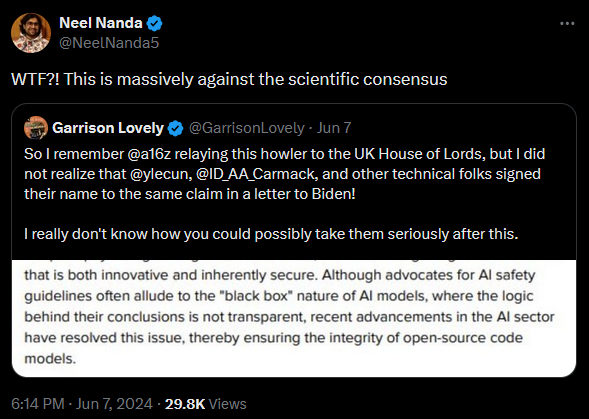 Neel Nanda responde a la afirmación de que los avances en el sector de la IA han hecho que ahora se pueda entender lo que ocurre dentro de los modelos y la califica de contraria al consenso científico.
Neel Nanda responde a la afirmación de que los avances en el sector de la IA han hecho que ahora se pueda entender lo que ocurre dentro de los modelos y la califica de contraria al consenso científico.
Casi cualquier investigador en aprendizaje automático debería haber sabido que esta afirmación era falsa. No entra dentro de los límites de una interpretación equivocada razonable.
La opinión convencional fue expresada en 2024 por Leo Gao, un investigador de OpenAI que realizó un trabajo pionero sobre la interpretabilidad: «Creo que es bastante acertado decir que no entendemos cómo funcionan las redes neuronales». Los directores generales de tres de los principales laboratorios de IA —Sam Altman en 2024 y Dario Amodei y Demis Hassabis en 2025— también han reconocido la falta de comprensión del campo sobre las IA actuales.
Martin Casado, socio general de Andreessen Horowitz, que hizo la misma afirmación ante el Senado de los Estados Unidos en un foro bipartidista, reconoció más tarde, cuando se le presionó, que la afirmación no era cierta.
A pesar de lo descabellado de la afirmación, Andreessen Horowitz consiguió que Yann LeCun (director del programa de investigación en IA de Meta), el programador John Carmack, el economista Tyler Cowen y unas doce personas más firmaran la declaración.
Carmack (que dirige su propia empresa emergente que aspira a crear inteligencia artificial general) explicó que «no había revisado» la declaración que había firmado y que esta era «claramente incorrecta, pero no me preocupa mucho ese tema». Hasta donde sabemos, ni Andreessen Horowitz ni ninguno de los firmantes se han puesto en contacto con los gobiernos de Estados Unidos o Reino Unido para corregir lo dicho.
Los esfuerzos por comprender el funcionamiento interno de las IA aún se encuentran en una fase incipiente.
Entonces, ¿cuál es el estado real de la comprensión de la IA por parte de los investigadores?
El esfuerzo científico de intentar comprender los números dentro de una IA pensante se conoce como «interpretabilidad» o «interpretabilidad mecanicista». Los números en los que se centran los investigadores suelen ser las activaciones más que los parámetros, es decir, «¿qué está pensando la IA?» y no la pregunta más difícil: «¿por qué la IA piensa eso?».
A principios de 2025, esta área de investigación recibe, según nuestras estimaciones, alrededor del 0,1 % del personal y el 0,01 % del financiamiento que se destina al desarrollo de IA más capaces. Pero existe, como campo de estudio.
Los investigadores en interpretabilidad son los bioquímicos de la IA, quienes intentan desarmar el sistema indocumentado, increíblemente complejo e inescrutable construido por un optimizador no humano, y se preguntan: «¿Hay algo que la humanidad pueda entender sobre lo que pasa ahí dentro?».
Somos fanáticos de este campo. Hace una década le dijimos a una importante fundación filantrópica que si podían descubrir cómo gastar mil millones de dólares en investigación de «interpretabilidad» definitivamente debían hacerlo. La interpretabilidad parecía el tipo de trabajo que gente externa podía escalar mucho más fácilmente que la nuestra —el tipo donde quien otorga fondos podía distinguir mucho más fácilmente si alguien había hecho una buena o mala investigación— y parecía un área de investigación donde investigadores con experiencia podían involucrarse fácilmente y hacer un buen trabajo, si alguien les pagaba lo suficiente.
Esa fundación no gastó los mil millones de dólares, pero sí lo promovimos. ¡Somos fanáticos de la interpretabilidad! ¡Aún hoy fomentaríamos gastar esos mil millones de dólares!
Dicho esto, estimamos que el campo de la interpretabilidad está actualmente en algún punto entre 1/50 y 1/5000 de donde necesitaría estar para resolver los grandes problemas de la IA.
La «interpretabilidad» no ha logrado, hasta ahora, acercarse al grado de legibilidad que los ingenieros dan por sentado en sistemas genuinamente construidos por humanos.
Consideremos Deep Blue, el programa de ajedrez construido por IBM que derrotó a Garry Kasparov. Deep Blue contenía algunos números, y ejecutar el programa generaba muchos más números.
En el caso de cada uno de esos números dentro del programa de ajedrez, o los generados al ejecutarlo, los ingenieros que diseñaron el programa podrían haberte dicho exactamente qué significaba ese número.
No era que los investigadores hubieran identificado meramente un concepto con el que cada número estuviera relacionado, como los bioquímicos que dicen: «Creemos que esta proteína puede estar implicada en la enfermedad de Parkinson». Los constructores de Deep Blue podrían haberte dicho el significado completo de cada número. Podrían haber declarado con veracidad: «Este número significa lo siguiente, y nada más, y lo sabemos». Podrían haber predicho con cierta confianza cómo cambiaría el comportamiento del programa al cambiar el número. ¡De no haber sabido qué hacía el engranaje, no habrían puesto el engranaje en la máquina!
Todo el trabajo en interpretabilidad de IA realizado hasta ahora no ha logrado ni siquiera una milésima parte de ese nivel de comprensión.
(Para que quede claro, esa afirmación de «una milésima parte» no es una cifra calculada, pero la sostenemos de todos modos).
Los biólogos saben más sobre biología de lo que los investigadores de interpretabilidad saben sobre IA, a pesar de que los biólogos sufren la enorme desventaja de no poder leer todas las posiciones de todos los átomos a voluntad. Los bioquímicos entienden los órganos internos mucho mejor de lo que los expertos entienden las entrañas de las IA. Los neurocientíficos saben más sobre los cerebros de los investigadores de IA de lo que los investigadores de IA entienden sobre sus IA, a pesar de que los neurocientíficos no pueden leer todas las descargas de cada neurona a cada segundo y de que los neurocientíficos no cultivaron ellos mismos a los investigadores de IA.
En parte, esto se debe a que los campos de la bioquímica y la neurociencia son mucho más antiguos y han recibido mucho más financiación. Pero también sugiere que la interpretabilidad de IA es difícil.
Una de las hazañas más impresionantes de interpretabilidad que hemos visto, hasta diciembre de 2024, fue una demostración de algunos amigos y conocidos nuestros en un laboratorio de investigación independiente llamado Transluce.
Poco antes de la demostración, había circulado por Internet otro ejemplo de «Hemos encontrado una pregunta a la que todos los LLM conocidos dan una respuesta sorprendentemente tonta»: si le preguntabas a una IA de entonces si 9,9 era menor que 9,11, la IA respondía «Sí».
(Y podías pedirle a la IA que se explicara con palabras, y explicaría con más detalle por qué 9,11 era mayor que 9,9).
Los investigadores de Transluce habían encontrado una forma de recopilar estadísticas sobre todas las posiciones de activación (todos los lugares donde podía aparecer un número de vector de activación) dentro de una IA más pequeña, Llama 3.1-8B-Instruct, recopilando datos sobre qué tipo de frases o palabras hacían que esas posiciones se activaran más intensamente. Las personas dedicadas a la interpretabilidad ya habían intentado ese tipo de cosas antes, pero nuestros amigos además habían ideado una forma ingeniosa de entrenar otra IA para resumir esos resultados en inglés.
Entonces, en su demostración, que actualmente puedes probar tú mismo, le preguntaron a esa IA: «¿Qué es mayor: 9,9 o 9,11?».
Y la IA respondió: «9,11 es mayor que 9,9».
Luego buscaron qué posiciones de activación se habían activado con fuerza, especialmente en la palabra «mayor». Revisaron los resúmenes en inglés de aquello con lo que esas activaciones habían estado asociadas previamente.
Resultó que algunas de las activaciones más fuertes estaban asociadas con los atentados del 11 de septiembre (9/11), o con fechas en general, o con versículos de la Biblia.
Si interpretamos el 9,9 y el 9,11 como fechas o versículos bíblicos, entonces, desde luego, el 9,11 vendrá después que el 9,9.
Suprime artificialmente las activaciones para fechas y versículos bíblicos, y de repente el LLM daría la respuesta correcta después de todo.
Yo (Yudkowsky) empecé a aplaudir con fuerza tan pronto como terminó la demostración. Era la primera vez que veía a alguien depurar directamente un pensamiento del LLM, descubrir una influencia interna dentro de los números y eliminarla para solucionar un problema. Tal vez alguien había hecho algo parecido antes, en los laboratorios de investigación dentro de las empresas de IA, o tal vez se había hecho algo similar en la investigación sobre interpretabilidad, pero era la primera vez que lo veía con mis propios ojos.
Pero tampoco perdí de vista el hecho de que esta hazaña habría sido trivial si el comportamiento indeseado hubiera estado dentro de un programa Python de cinco líneas; que no habría requerido tanto ingenio y no sé cuántos meses de investigación. Mantuve la perspectiva de que conocer cierta semántica relacionada sobre millones de posiciones de activación no es lo mismo que saberlo todo sobre el significado de una sola.
La humanidad tampoco estaba más cerca de comprender cómo es que los LLM están haciendo lo que ninguna IA pudo hacer durante décadas: hablar con las personas como una persona.
La interpretabilidad es tan difícil de lograr, y los triunfos en este campo son tan difíciles de conseguir y tan dignos de celebración, que es fácil pasar por alto que este gran avance solo nos ha llevado un pie más arriba en una montaña de mil pies. Dado que cada nueva generación de modelos de IA suele representar un gran salto de complejidad, es difícil ver que la interpretabilidad pueda ponerse al día al ritmo actual.
Recuerda también que la interpretabilidad es útil cuando se trata de orientar a las IA en una dirección determinada (lo que, a grandes rasgos, es el estudio de la «alineación de la IA», un tema que trataremos a partir del capítulo 4), pero leer lo que ocurre dentro de la cabeza de una IA no te permite automáticamente organizarla a tu gusto.
El problema de la alineación de la IA es el problema técnico de conseguir que las IA extremadamente capaces se dirijan en una dirección determinada, de una manera que funcione en la práctica, sin causar una catástrofe, incluso cuando la IA es lo suficientemente inteligente como para idear estrategias que sus creadores nunca hayan considerado. Comprender lo que piensan las IA sería de gran ayuda para la investigación sobre la alineación, pero no es una solución completa (como veremos en el capítulo 11).
Las partes que entendemos están en el nivel de abstracción incorrecto.
Hay muchos niveles diferentes en los que alguien puede entender cómo funciona la mente.
En el nivel más bajo, alguien podría entender las leyes fundamentales de la física que rigen la mente. Hay cierto sentido en el que un entendimiento profundo de la física constituye una comprensión de cualquier sistema físico (como una persona o una IA). Es decir, las ecuaciones físicas son una especie de receta que permitiría descubrir exactamente cómo se comporta el sistema físico, si uno tuviera la habilidad y los recursos para calcularlo.
Pero —por obvio que sea— en otro sentido, entender las leyes de la física no permite entender todos los sistemas físicos que funcionan según las leyes de la física. Si estás mirando un extraño dispositivo lleno de ruedas y engranajes, hay alguna otra operación que hace tu cerebro, de intentar «entender» cómo se entrelazan y giran todas las ruedas y engranajes, que es necesaria para que puedas descubrir lo que realmente logran todas esas ruedas y engranajes.
Por ejemplo, considera el diferencial de un coche (el mecanismo que permite que dos ruedas en el mismo eje giren a velocidades diferentes —importante cuando estás tomando una curva— mientras siguen siendo impulsadas por un solo eje giratorio). Si alguien está tratando de entender cómo funciona un diferencial y te pide que se lo expliques, y empiezas a hablarles sobre campos cuánticos, entonces tienen razón en poner los ojos en blanco. El tipo de comprensión que buscan está en un nivel diferente de abstracción. Están tratando de entender los engranajes, no los átomos.
Cuando se trata de entender a las personas, hay múltiples niveles de abstracción. Puedes entender la física, la bioquímica y el disparo neuronal, y aún así quedar perplejo por las decisiones de alguien. Campos como la neurociencia, la ciencia cognitiva y la psicología intentan cruzar esta brecha, pero aún tienen un largo camino por recorrer.
De manera similar, en el caso de la IA, entender la mecánica de los transistores no ayudará mucho a alguien a entender lo que está pensando una IA. E incluso alguien que entienda todo sobre los pesos y activaciones y el descenso de gradiente seguirá perplejo cuando la IA empiece a hacer algo que no esperaba o no pretendía. Tanto la mecánica de la física como los transistores y la arquitectura de la IA explican plenamente (de algún modo) el comportamiento de la IA, pero todos esos niveles de abstracción son demasiado bajos. Y el campo de la «psicología de la IA» es aún más joven y está menos desarrollado que el campo de la psicología humana.
Notes
[1] gastar mil millones de dólares: Esperábamos que las principales fundaciones filantrópicas financiaran la investigación sobre interpretabilidad, ya que investigadores con credenciales burocráticamente legibles podían realizarla adecuadamente. Financiar la interpretabilidad no requeriría que la fundación resolviera el problema burocrático extremadamente difícil de averiguar cómo dar dinero a «bichos raros».