Las ideas «obvias» toman tiempo
Es difícil dar con ideas en el campo de la IA, incluso cuando parecen sencillas y obvias en retrospectiva. Es importante entender esto porque hacer IA de la manera correcta probablemente requerirá muchas ideas. Pero por muy sencillas que puedan sonar en retrospectiva, encontrarlas puede tomar décadas de arduo trabajo.
Con ese propósito, destacaremos algunas de las ideas que impulsan las IA modernas.
Si sabes de programación, por ejemplo, podrías leer el capítulo 2 del libro y pensar que este asunto del «descenso de gradiente» suena tan sencillo que podrías simplemente salir corriendo a probarlo. Pero si lo hicieras, probalmente te toparías pronto con algún tipo de error. Quizás tu programa se bloquearía con un error de coma flotante porque los números en uno de los pesos se habrían vuelto demasiado grandes.
En el siglo XX, nadie sabía cómo hacer que el descenso de gradiente funcionara en una red neuronal con varias capas de números intermedios entre los datos de entrada y los de salida. Para evitar problemas, los programadores tenían que aprender todo tipo de trucos, como inicializar todos los pesos de formas ligeramente inteligentes que evitaran que se volvieran demasiado grandes. Por ejemplo, en lugar de inicializar todos los pesos a un número aleatorio entre 0 y 1 (o un número aleatorio con media 0 y desviación estándar 1), tienes que inicializar los pesos así y luego dividirlos todos por una constante diseñada para asegurarte de que los números de la siguiente capa tampoco se vuelvan demasiado grandes durante la operación.
El descenso de gradiente se topa con problemas cuando se ejecuta en fórmulas complicadas con muchos pasos o «capas», y dividir los números aleatorios iniciales por una constante es una de las ideas principales que permite el «aprendizaje profundo». Ese truco no se inventó sino hasta seis décadas después de que las redes neuronales fueran propuestas originalmente en 1943.
La idea de usar cálculo para ajustar los parámetros se discutió por primera vez en 1962 y se aplicó por primera vez a la idea de redes neuronales con más de una capa en 1967. Y no se popularizó realmente sino hasta la publicación de un artículo en 1986 (del cual Geoffrey Hinton fue coautor, una razón por la cual se le conoce como el «padrino de la IA»). No obstante, cabe destacar que la idea más general de usar cálculo en preguntas diferenciables para moverse en la dirección de una respuesta correcta —por ejemplo, para calcular una raíz cuadrada— fue inventada por Isaac Newton.
Otro truco clave es el siguiente. En el libro, damos un ejemplo de operaciones de descenso de gradiente:
Multiplicaré cada número de entrada por el peso del primer parámetro, luego lo sumaré al peso del segundo parámetro, después lo sustituiré por cero si es negativo, y luego…
Esta lista de operaciones no es ningún error. La multiplicación, la suma y «sustituirlo por cero si es negativo» son, más o menos, las tres operaciones fundamentales de una red neuronal. Las dos primeras son los operadores que componen una «multiplicación matricial», y la última introduce una «no linealidad» y, por lo tanto, permite que la red aprenda funciones no lineales.
La fórmula para «sustituirlo por cero si es negativo» es
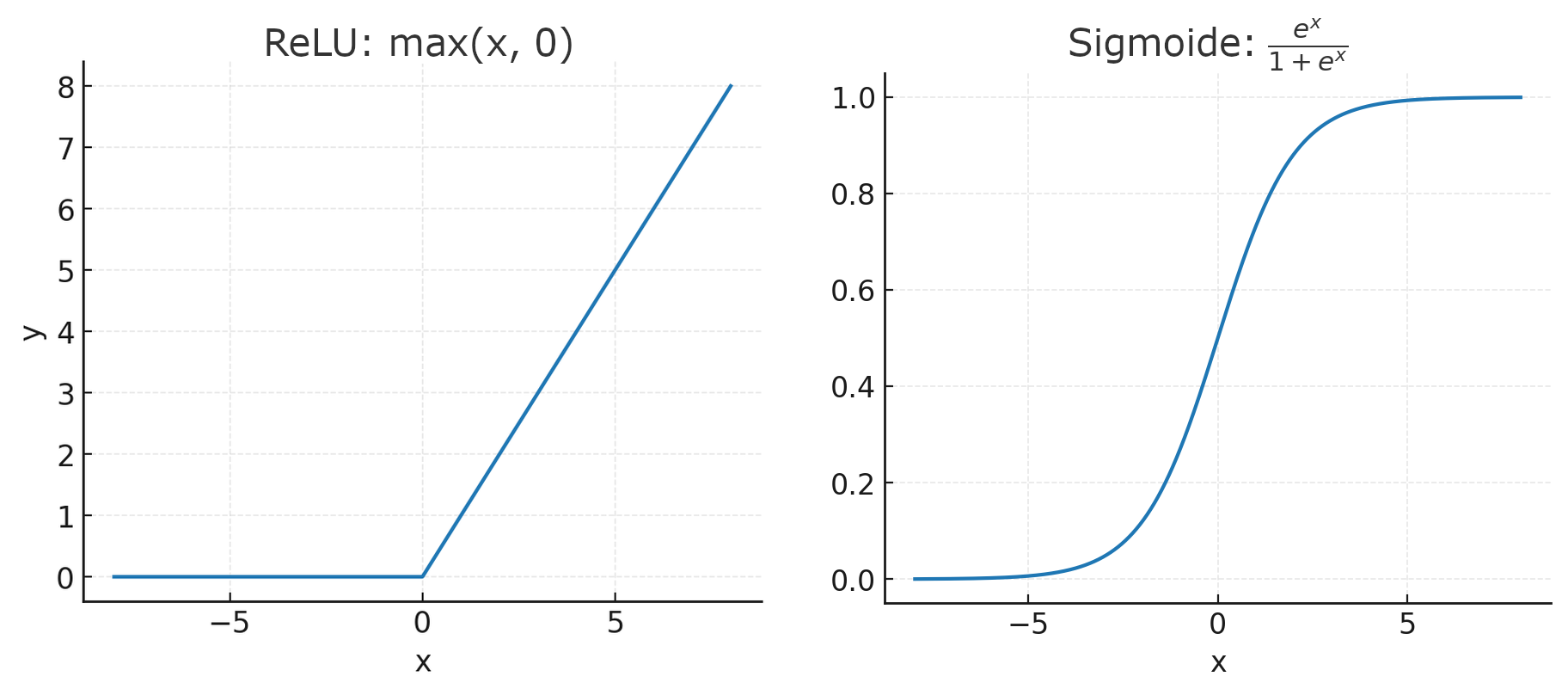
Había buenas razones para suponer que la fórmula «sigmoide», más complicada, funcionaría. Desde una perspectiva superficial, hace que los datos de salida oscilen de forma sensata entre 0 y 1 de manera fluida; y desde una perspectiva más profunda, tiene algunas conexiones útiles con la teoría de la probabilidad. Incluso algunas redes neuronales profundas modernas utilizan algo parecido a una sigmoide en algunos pasos. Pero si solo vas a utilizar una no linealidad, una ReLU funciona mucho mejor.
El problema de la fórmula sigmoide es que tiende a hacer que muchos de los datos de salida tengan gradientes muy pequeños. Y si la mayoría de los gradientes son muy pequeños, el descenso de gradiente deja de funcionar, al menos, a menos que conozcas el truco moderno de dar pasos de gradiente más grandes cuando los gradientes pequeños siempre apuntan a la misma dirección. (Hasta donde sabemos, este truco apareció por primera vez en la literatura en 2012, cuando fue propuesto por Geoffrey Hinton).
«Haz que tus números aleatorios iniciales sean más pequeños para que sus sumas multiplicadas no sean enormes», «usa max(x, 0) en lugar de una fórmula complicada» y «da pasos más grandes cuando los gradientes diminutos sigan apuntando a la misma dirección» pueden parecer ideas extrañamente simples como para no haberse inventado durante décadas, especialmente porque, en retrospectiva, parecen obvias para un programador que entiende todo esto. Esta es una lección de importancia sobre cómo funcionan la ciencia y la ingeniería en la vida real.
Incluso cuando existe una solución sencilla y práctica para algún reto de ingeniería, a menudo los investigadores no la encuentran sino hasta que han intentado y fracasado durante décadas. No puedes confiar en que los investigadores la vean tan pronto como una solución adquiere importancia. No puedes confiar en que la vean en los próximos dos años. Incluso si una solución parece obvia en retrospectiva, a veces el campo tropieza durante décadas sin ella.
Nos estamos adelantando un poco a los recursos en línea del capítulo 2, pero esta es una lección que hay que tener en cuenta en la parte III del libro, cuando discutamos cómo la humanidad no está preparada para el desafío que plantea la superinteligencia artificial.
Si el precio de que algunos inventores locos sigan adelante a trompicones es que todos los habitantes de la Tierra mueran durante esta incómoda etapa infantil, no debemos permitir que los inventores locos continúen con sus tropiezos. Los inventores locos protestarán diciendo que no hay forma de que puedan encontrar una solución sencilla y robusta sin que se les permita dar tumbos durante unas décadas; dirán que no es realista esperar que lo resuelvan de antemano.
Es de esperar que para todos los que no sean inventores locos resulte obvio que, si estas afirmaciones son ciertas, deberíamos poner fin a sus esfuerzos. Pero ese es un tema que retomaremos en la parte III del libro, después de completar el argumento de que la superinteligencia artificial tendría los medios, el motivo y la oportunidad de extinguir a la humanidad.
* Las arquitecturas más recientes utilizarán funciones más sofisticadas. Por ejemplo, la arquitectura Llama 3.1 descrita a continuación utiliza la función «SwiGLU», que tiene una fórmula complicada que no reproduciremos aquí. El creador de la fórmula ni siquiera sabe por qué funciona, y afirma: «No ofrecemos ninguna explicación de por qué estas arquitecturas parecen funcionar; atribuimos su éxito, como todo lo demás, a la benevolencia divina».