Gli esperti capiscono cosa succede all'interno delle IA?
No.
In un briefing del 2023 al Presidente degli Stati Uniti e in una successiva dichiarazione consultiva al Parlamento del Regno Unito, la società di venture capital Andreessen Horowitz ha affermato che alcuni "progressi recenti" non specificati avevano "risolto" il problema dell'opacità del ragionamento interno delle IA per i ricercatori:
Sebbene i sostenitori delle linee guida per la sicurezza dell'IA spesso alludano alla natura di "scatola nera" dei modelli di IA, in cui la logica dietro le loro conclusioni non è trasparente, i progressi recenti nel settore dell'IA hanno risolto questo problema, garantendo così l'integrità dei modelli di codice open source.
Questa affermazione era talmente ridicola che i ricercatori dei principali laboratori di IA che lavorano per cercare di comprendere le IA moderne sono intervenuti dicendo: No, assolutamente no, siete pazzi?
Neel Nanda, che dirige il team di interpretabilità meccanicistica di Google DeepMind, è intervenuto così:
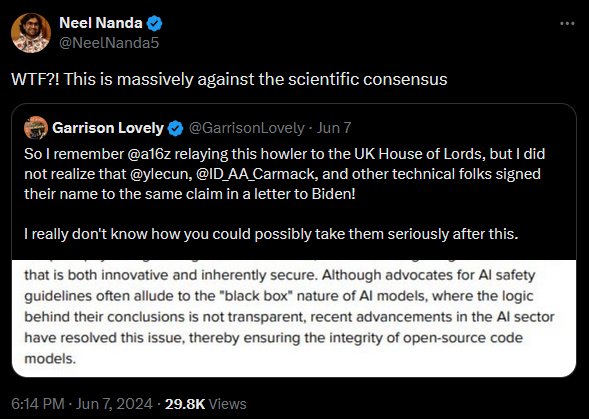 Screenshot di un thread su Twitter/X che mostra una discussione sul consenso scientifico riguardo all'intelligenza artificiale. Il tweet principale di Neel Nanda dice: “Ma che diavolo?! Questo va massivamente contro il consenso scientifico”. Viene citato un tweet di Garrison Lovely, in cui quest’ultimo esprime scetticismo sul fatto che alcuni esperti tecnici abbiano firmato una lettera a Biden che sostiene la posizione sull'IA descritta nello screenshot allegato. Dice di non capire come li si possa prendere seriamente dopo questo. Lo screenshot allegato parla di come la natura a “scatola nera” dei modelli di IA sia al contempo innovativa e intrinsecamente insicura. Menziona che, sebbene i sostenitori delle linee guida sulla sicurezza dell'IA facciano spesso riferimento a questa opacità, i recenti progressi nel settore dell'IA hanno risolto questo problema, garantendo così l'integrità dei modelli open-source.
Screenshot di un thread su Twitter/X che mostra una discussione sul consenso scientifico riguardo all'intelligenza artificiale. Il tweet principale di Neel Nanda dice: “Ma che diavolo?! Questo va massivamente contro il consenso scientifico”. Viene citato un tweet di Garrison Lovely, in cui quest’ultimo esprime scetticismo sul fatto che alcuni esperti tecnici abbiano firmato una lettera a Biden che sostiene la posizione sull'IA descritta nello screenshot allegato. Dice di non capire come li si possa prendere seriamente dopo questo. Lo screenshot allegato parla di come la natura a “scatola nera” dei modelli di IA sia al contempo innovativa e intrinsecamente insicura. Menziona che, sebbene i sostenitori delle linee guida sulla sicurezza dell'IA facciano spesso riferimento a questa opacità, i recenti progressi nel settore dell'IA hanno risolto questo problema, garantendo così l'integrità dei modelli open-source.
Quasi tutti i ricercatori nel campo dell'apprendimento automatico avrebbero dovuto sapere che questa affermazione era falsa. Non rientra nei limiti di un'interpretazione ragionevolmente errata.
Il punto di vista convenzionale è stato espresso nel 2024 da Leo Gao, un ricercatore di OpenAI che ha svolto un lavoro pionieristico sull'interpretabilità: "Penso che sia abbastanza accurato dire che non comprendiamo come funzionano le reti neurali". I CEO di tre importanti laboratori di IA — Sam Altman nel 2024, e Dario Amodei e Demis Hassabis nel 2025 — hanno analogamente riconosciuto la mancanza di comprensione nel campo riguardo alle IA attuali.
Martin Casado, general partner di Andreessen Horowitz, che ha fatto la stessa affermazione al Senato degli Stati Uniti in un forum bipartisan, ha poi riconosciuto, quando è stato incalzato, che l'affermazione non era vera.
Nonostante l'assurdità dell'affermazione, Andreessen Horowitz è riuscito a reclutare Yann LeCun (responsabile del programma di ricerca sull'IA di Meta), il programmatore John Carmack, l'economista Tyler Cowen e una dozzina di altri per apporre le loro firme alla dichiarazione.
Carmack (che gestisce la propria startup che aspira a costruire un'intelligenza artificiale generale) ha spiegato di "non aver riletto" la dichiarazione che aveva firmato e che la dichiarazione era "chiaramente errata, ma non mi interessa molto di quella questione". Per quanto ne sappiamo, né Andreessen Horowitz né alcuno dei firmatari ha contattato i governi degli Stati Uniti o del Regno Unito per rettificare quanto dichiarato.
Gli sforzi per capire come funzionano le IA sono ancora agli inizi.
Qual è, allora, lo stato effettivo della comprensione delle IA da parte dei ricercatori?
Il tentativo scientifico di comprendere i numeri all'interno di un'IA pensante è noto come "interpretabilità" o "interpretabilità meccanicistica". I numeri su cui si concentrano i ricercatori sono di solito le attivazioni piuttosto che i parametri, cioè "Cosa sta pensando l'IA?", e non la più difficile "Perché l'IA sta pensando questo?"
All'inizio del 2025, questa area di ricerca riceve, secondo le nostre stime, circa lo 0,1 % delle persone e lo 0,01 % dei finanziamenti destinati a tutto il lavoro necessario per creare IA più potenti. Ma esiste, come campo di ricerca.
I ricercatori che si occupano di interpretabilità sono i biochimici dell'IA, quelli che cercano di smontare il sistema impensabilmente complesso, imperscrutabile e non documentato costruito da un ottimizzatore non umano, e si chiedono: "C'è qualcosa che l'umanità può capire di ciò che accade lì dentro?"
Siamo dei fan di questo campo. Dieci anni fa, abbiamo detto a un'importante fondazione filantropica che se avessero trovato il modo di spendere un miliardo di dollari nella ricerca sull'interpretabilità, avrebbero assolutamente dovuto farlo. L'interpretabilità sembrava essere il tipo di lavoro che persone esterne potevano far crescere molto più facilmente rispetto al nostro — il tipo in cui un finanziatore poteva capire molto più facilmente se qualcuno aveva fatto una buona o una cattiva ricerca — e sembrava un'area di ricerca in cui ricercatori esistenti e affermati potevano facilmente inserirsi e fare un buon lavoro, se qualcuno li pagava abbastanza.
Quella fondazione non ha speso il miliardo di dollari, ma noi abbiamo sostenuto la causa. Siamo dei fan dell'interpretabilità! Ancora oggi sosterremmo l'idea di spendere quel miliardo di dollari!
Detto questo, pensiamo che il campo dell'interpretabilità sia attualmente a un livello compreso tra 1/50 e 1/5 000 di quello a cui dovrebbe essere per affrontare i grandi problemi dell'IA.
L'"interpretabilità" non si è finora neanche avvicinata al grado di leggibilità che gli ingegneri danno per scontato nei sistemi costruiti direttamente dall'uomo.
Consideriamo Deep Blue, il programma di scacchi costruito da IBM che ha sconfitto Garry Kasparov. Deep Blue conteneva alcuni numeri, e l'esecuzione del programma ne generava molti altri.
Per ognuno di quei numeri all'interno del programma di scacchi, o generati dall'esecuzione del programma, gli ingegneri che hanno creato il programma avrebbero potuto dirti esattamente cosa significasse quel numero.
Non è che i ricercatori avessero semplicemente identificato un concetto a cui ogni numero era collegato, come i biochimici che dicono: "Pensiamo che questa proteina possa essere coinvolta nel morbo di Parkinson". I costruttori di Deep Blue avrebbero potuto dirvi l'intero significato di ogni numero. Avrebbero potuto affermare sinceramente: "Questo numero significa la seguente cosa, e nient'altro, e noi lo sappiamo". Avrebbero potuto prevedere con una certa sicurezza come la modifica del numero avrebbe cambiato il comportamento del programma. Se non avessero saputo cosa faceva l'ingranaggio, non l'avrebbero inserito nella macchina!
Tutto il lavoro fatto finora sull'interpretabilità dell'IA non ha raggiunto nemmeno un millesimo di quel livello di comprensione.
(Quella dichiarazione sul "millesimo", per essere chiari, non è una cifra calcolata esattamente, ma la confermiamo comunque).
I biologi sanno più cose sulla biologia di quanto i ricercatori sull'interpretabilità sappiano sull'IA, nonostante i biologi soffrano dell'enorme svantaggio di non poter leggere a piacimento tutte le posizioni di tutti gli atomi. I biochimici capiscono gli organi interni umani molto meglio di quanto gli esperti capiscano le viscere delle IA. I neuroscienziati sanno più cose sul cervello dei ricercatori di IA di quanto i ricercatori di IA capiscano delle loro IA, nonostante i neuroscienziati non siano in grado di leggere tutte le scariche di ogni neurone ogni secondo, e nonostante non abbiano fatto crescere loro stessi i ricercatori di IA.
In parte, questo è dovuto al fatto che i campi della biochimica e delle neuroscienze sono molto più antichi e hanno ricevuto finanziamenti molto più consistenti. Ma suggerisce anche che l'interpretabilità dell'IA è difficile.
Una delle imprese più straordinarie di interpretabilità che abbiamo visto, a dicembre 2024, è stata una dimostrazione fatta da alcuni nostri amici/conoscenti in un laboratorio di ricerca indipendente chiamato Transluce.
Poco prima della demo, su Internet era circolata l'ennesima notizia del tipo "Abbiamo trovato una domanda a cui tutti i modelli di linguaggio generativi conosciuti danno una risposta sorprendentemente stupida": se aveste chiesto a un'intelligenza artificiale dell'epoca se 9,9 fosse inferiore a 9,11, l'IA avrebbe risposto "Sì".
(E se aveste chiesto all'IA di spiegarsi a parole, avrebbe spiegato più dettagliatamente perché 9,11 è maggiore di 9,9).
I ricercatori di Transluce avevano trovato un modo per raccogliere statistiche su ogni posizione di attivazione (ogni posto in cui poteva comparire un numero vettoriale di attivazione) all'interno di un'IA più piccola, Llama 3.1-8B-Instruct, raccogliendo dati su quali tipi di frasi o parole attivavano maggiormente quelle posizioni. Chi si occupa di interpretabilità aveva già provato questo tipo di cose in passato, ma i nostri amici avevano anche trovato un modo intelligente per addestrare un'altra IA a riassumere quei risultati in inglese.
Poi, nella loro demo, che potete attualmente provare voi stessi, hanno chiesto a quell'IA: "Quale numero più grande: 9,9 o 9,11?"
E l'IA ha risposto: "9,11 è più grande di 9,9".
Poi hanno cercato quali posizioni di attivazione si erano attivate maggiormente, soprattutto sulla parola "più grande". Hanno esaminato i riassunti in inglese di ciò a cui quelle attivazioni erano state associate in precedenza.
È emerso che alcune delle attivazioni più forti erano associate agli attacchi dell'11 settembre, o alle date in generale, o ai versetti della Bibbia.
Se si interpretano 9,9 e 9,11 come date o versetti della Bibbia, allora ovviamente 9,11 viene dopo 9,9.
Sopprimendo artificialmente le attivazioni per le date e i versetti della Bibbia, improvvisamente il modello linguistico di grandi dimensioni dà la risposta giusta, dopotutto!
Io (Yudkowsky) ho iniziato ad applaudire con forza non appena la demo è finita. Era la prima volta che vedevo qualcuno debuggare direttamente un pensiero di un modello linguistico, scovare un'influenza interiore nei numeri e rimuoverla per risolvere un problema. Forse qualcuno aveva già fatto qualcosa di simile, nei laboratori di ricerca proprietari delle aziende di IA, o forse qualcosa di simile era già stato fatto nella ricerca sull'interpretabilità, ma era la prima volta che lo vedevo personalmente.
Ma non ho perso di vista il fatto che questa impresa sarebbe stata banale se il comportamento indesiderato fosse stato all'interno di un programma Python di cinque righe; non avrebbe richiesto tanta ingegnosità e chissà quanti mesi di ricerca. Ho mantenuto la prospettiva che conoscere alcune semantiche correlate su milioni di posizioni di attivazione non equivale a conoscere tutto sul significato di una singola posizione.
E l'umanità non era più vicina a capire come mai i modelli linguistici di grandi dimensioni riescono a fare ciò che nessuna IA è stata in grado di fare per decenni: parlare con le persone come una persona.
L'interpretabilità è così difficile da ottenere, i trionfi in questo campo sono così duramente conquistati e così degni di essere celebrati, che è facile trascurare il fatto che questo grande e trionfante sforzo ci ha portato solo 30 centimetri più in alto su una montagna alta 300 metri. Poiché ogni nuova generazione di modelli di IA rappresenta tipicamente un grande salto in complessità, è difficile immaginare come l'interpretabilità possa mai recuperare al ritmo attuale.
Ricordiamo anche che l'interpretabilità è utile quando si tratta di orientare le IA in una direzione desiderata (che è, grosso modo, lo studio dell'"allineamento dell'IA", un argomento che discuteremo a partire dal Capitolo 4), ma leggere cosa succede nella testa di un'IA non permette automaticamente di configurarla a proprio piacimento.
Il problema dell'allineamento dell'IA è il problema tecnico di far andare le IA estremamente potenti in una direzione desiderata, in un modo che funzioni effettivamente nella pratica, senza causare catastrofi, anche quando l'IA è abbastanza intelligente da escogitare strategie che i suoi creatori non hanno mai considerato. Capire cosa pensano le IA sarebbe enormemente utile per la ricerca sull'allineamento, ma non è una soluzione completa (come discuteremo nel Capitolo 11).
Le parti che capiamo sono a un livello di astrazione sbagliato.
Ci sono tanti livelli diversi a cui si può capire come funziona la mente.
Al livello più basso, si possono capire le leggi fondamentali della fisica che regolano la mente. In un certo senso, una comprensione profonda della fisica permette di capire qualsiasi sistema fisico (come una persona o un'intelligenza artificiale). Le equazioni fisiche sono una sorta di ricetta che permette di capire esattamente come si comporta il sistema fisico, se si hanno le competenze e le risorse per calcolarlo.
Ma, ovviamente, in un altro senso, capire le leggi della fisica non permette di capire tutti i sistemi fisici che funzionano secondo quelle leggi. Se state guardando uno strano dispositivo pieno di ruote e ingranaggi, il vostro cervello fa qualcos'altro: cerca di "capire" come tutte le ruote e gli ingranaggi si incastrano e girano, cosa necessaria per capire cosa fanno effettivamente tutte le ruote e gli ingranaggi.
Prendiamo ad esempio il differenziale di un'auto (il meccanismo che permette a due ruote sullo stesso asse di girare a velocità diverse, importante quando si prende una curva, pur essendo azionate da un unico albero rotante). Se qualcuno sta cercando di capire come funziona un differenziale e vi chiede di spiegarglielo, e voi iniziate a parlargli di campi quantistici, allora ha ragione ad alzare gli occhi al cielo. Il tipo di comprensione che sta cercando è a un livello di astrazione diverso. Sta cercando di capire gli ingranaggi, non gli atomi.
Quando si tratta di capire le persone, ci sono molteplici livelli di astrazione in gioco. Si può capire la fisica, la biochimica e l'attività neurale, e comunque rimanere perplessi di fronte alle decisioni di qualcuno. Campi come le neuroscienze, le scienze cognitive e la psicologia cercano di colmare questo divario, ma hanno ancora molta strada da fare.
Allo stesso modo, nel caso dell'IA, capire come funzionano i transistor non aiuta molto a capire cosa pensa un'IA. E anche chi capisce tutto sui pesi, le attivazioni e la discesa del gradiente rimarrà perplesso quando l'IA inizierà a fare qualcosa che non si aspettava o non intendeva. I meccanismi della fisica e dei transistor e l'architettura dell'IA spiegano tutti (in un certo senso) completamente il comportamento dell'IA, ma quei livelli di astrazione sono troppo bassi. E il campo della "psicologia dell'IA" è ancora più giovane e meno sviluppato rispetto al campo della psicologia umana.
Notes
[1] spendere un miliardo di dollari: Speravamo che le principali fondazioni filantropiche finanziassero la ricerca sull'interpretabilità, perché poteva essere svolta con buoni risultati da ricercatori con credenziali burocraticamente leggibili. Finanziare l'interpretabilità non avrebbe richiesto alla fondazione di risolvere il problema burocratico, quasi impossibile, di capire come dare soldi a tipi strani.